This is part 6 in a series explaining how pipes works and what you can do with it. The article before this showed how to embed tweets into RSS feeds created by pipes.
Some sites have working RSS feeds that can be used to easily feed them into pipes, but they hide them. Regular discovery can’t work when the feed is not linked in the head of a page, which is exactly what happens sometimes. The biggest offender here is probably YouTube. But since the feeds do exist and their url follows a known scheme, pipes can access them anyway.
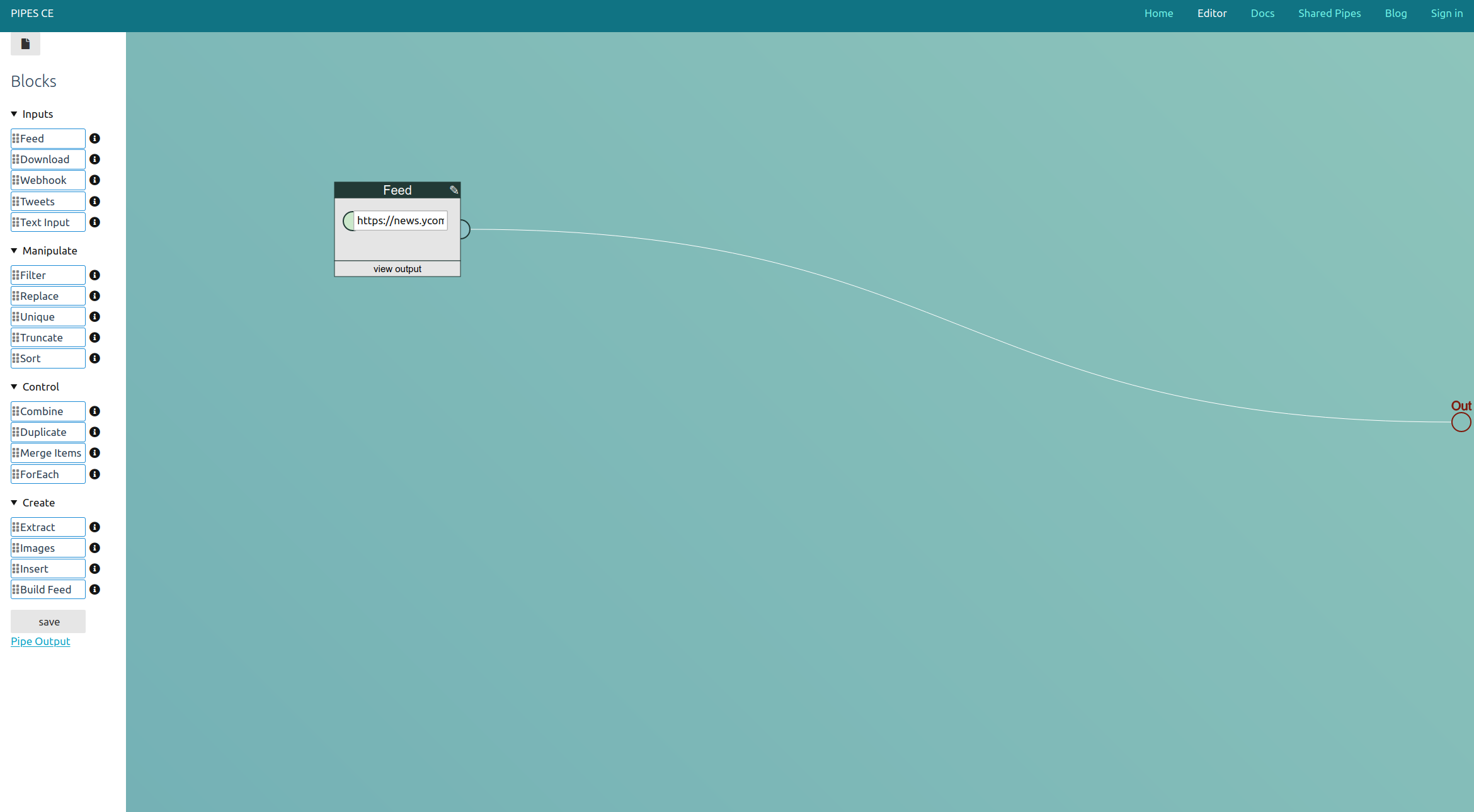
Let’s say I want to see all new videos added to the T90Official Age of Empires 2 channel. Load that page:

All we need is the url of the channel, https://www.youtube.com/channel/UCZUT79WUUpZlZ-XMF7l4CFg. Some channels also have a nicer to look at user url, like https://www.youtube.com/user/GamersNexus. That would also work.
Create a new pipe, drag a feed block from the left toolbar into the editor area and connect it to the pipe output to the right:
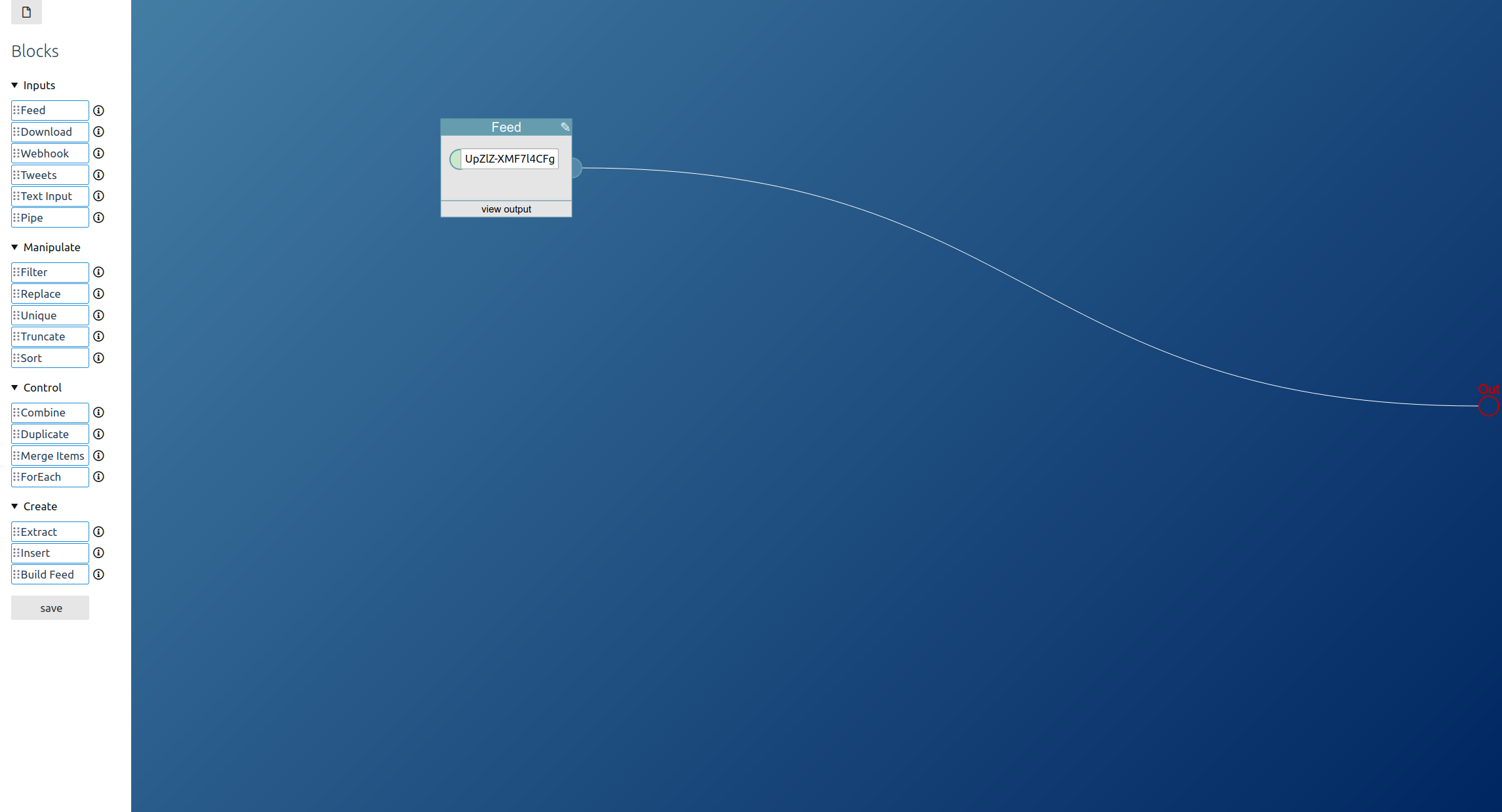
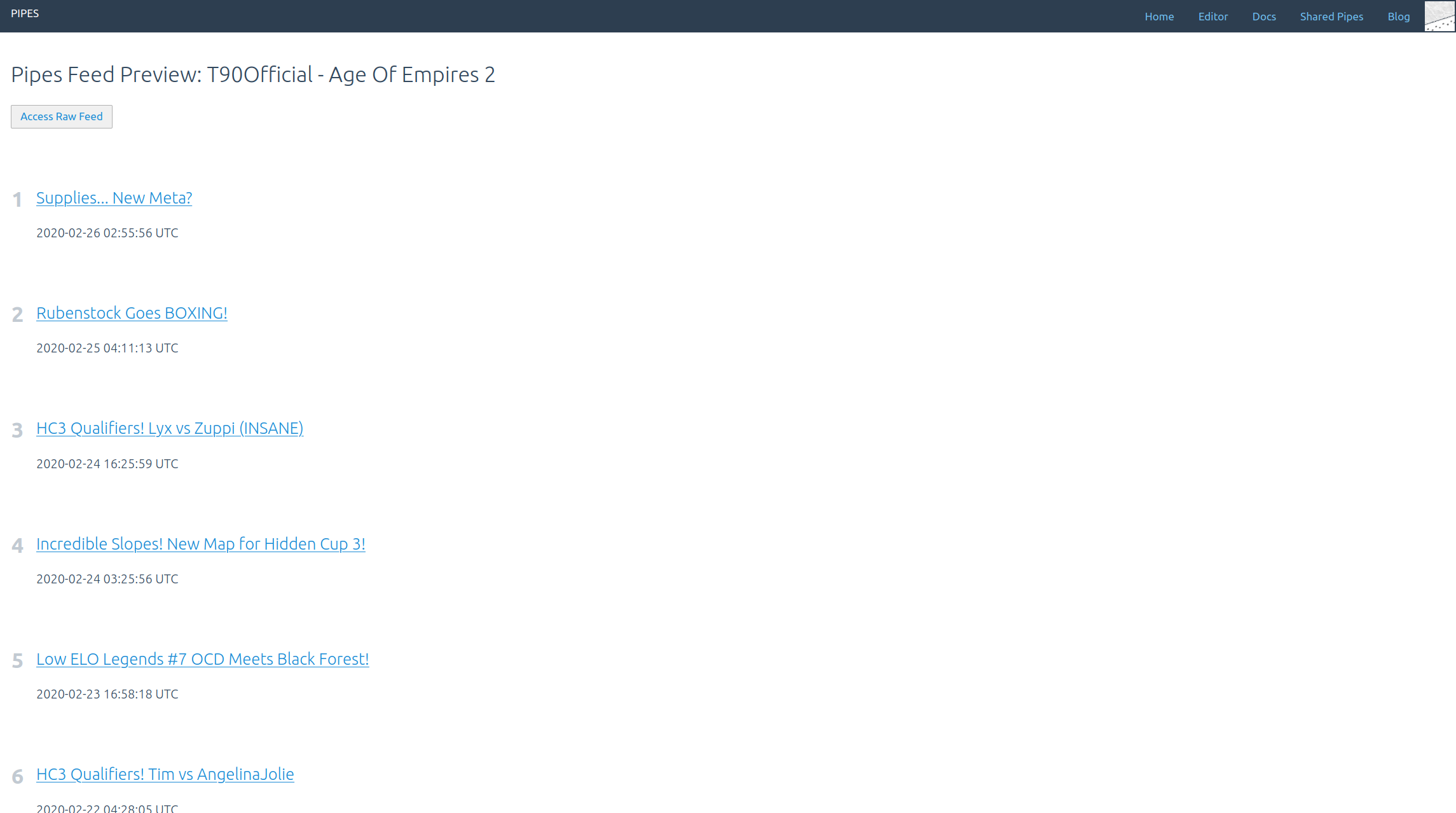
Now the created feed contains items with links to all new uploaded videos:
The second YouTube element that can be accessed are playlists. For example the game rating discussions by GamersGlobal:
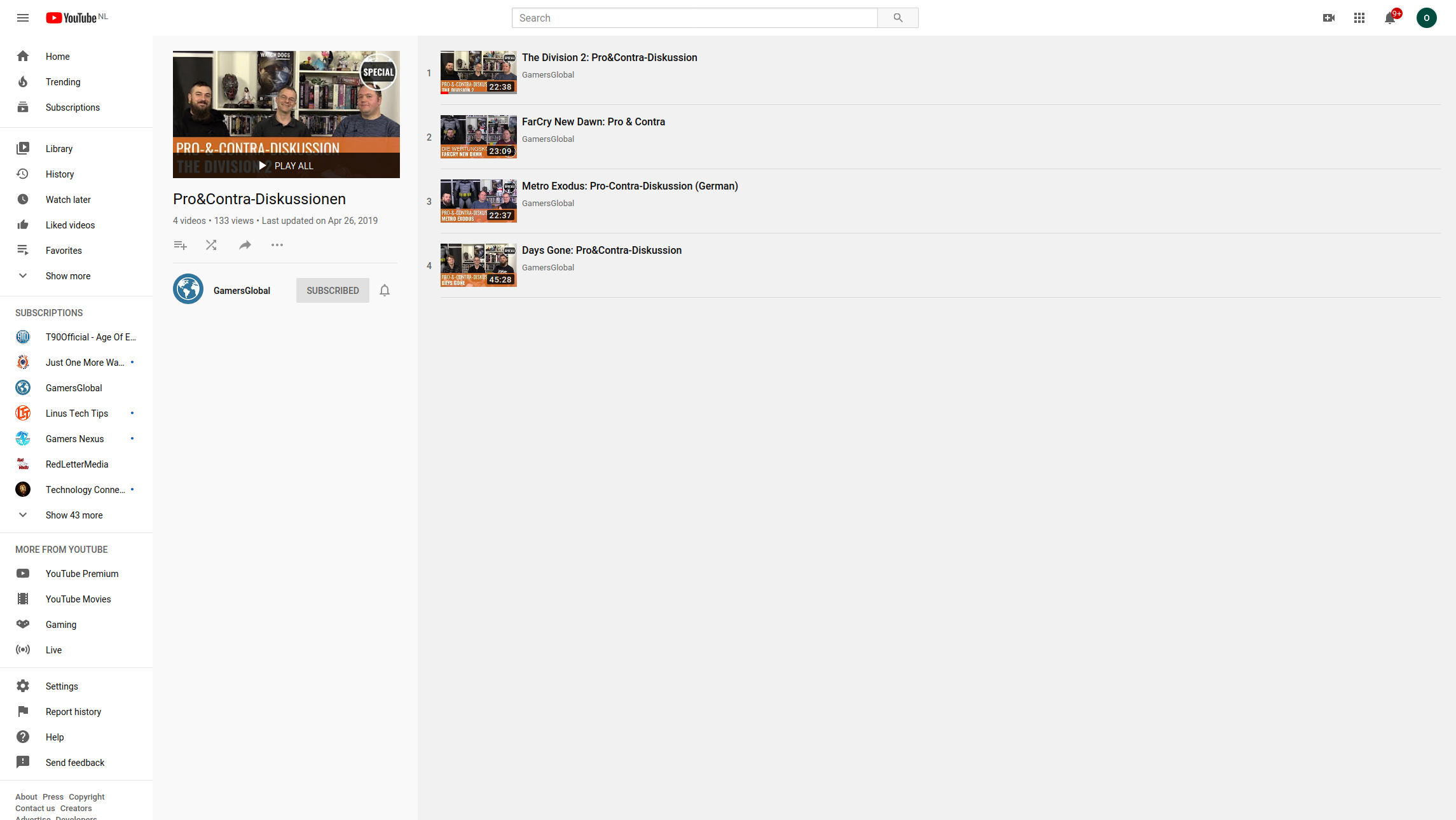
Set the url https://www.youtube.com/playlist?list=PLK9Cx_P99XLIBMkdW48UMA8OCnwBXUEVZ as target of a feed block. And the feed will now contain the videos in the playlist:
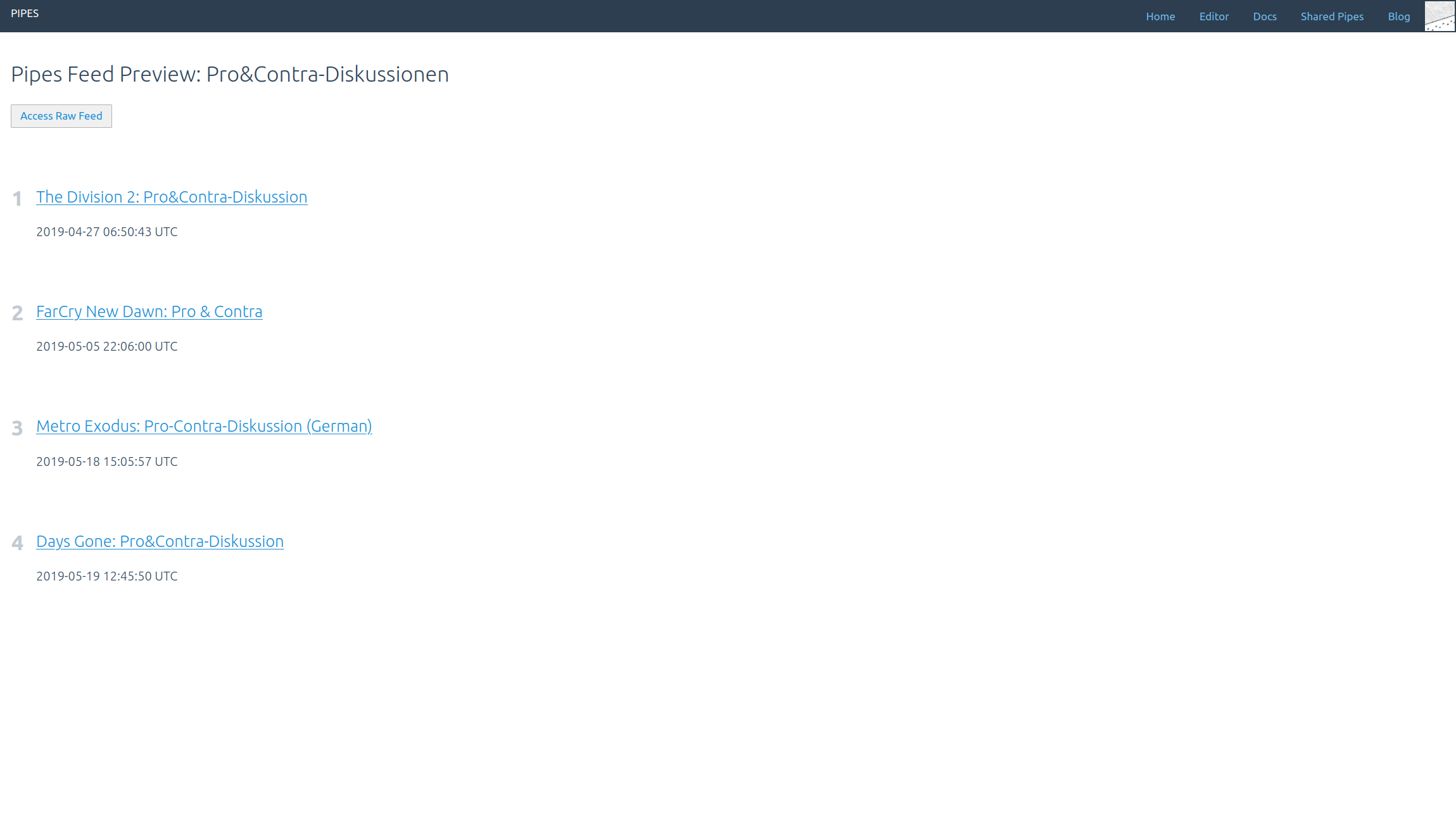
Both type of feeds get updated as one would expect when new videos get added.
Having those feeds is useful to filter out videos you don’t like, combine multiple channels into one or just to be notified about new videos of your favorite channel not on the YouTube website or app, but in your feed reader.