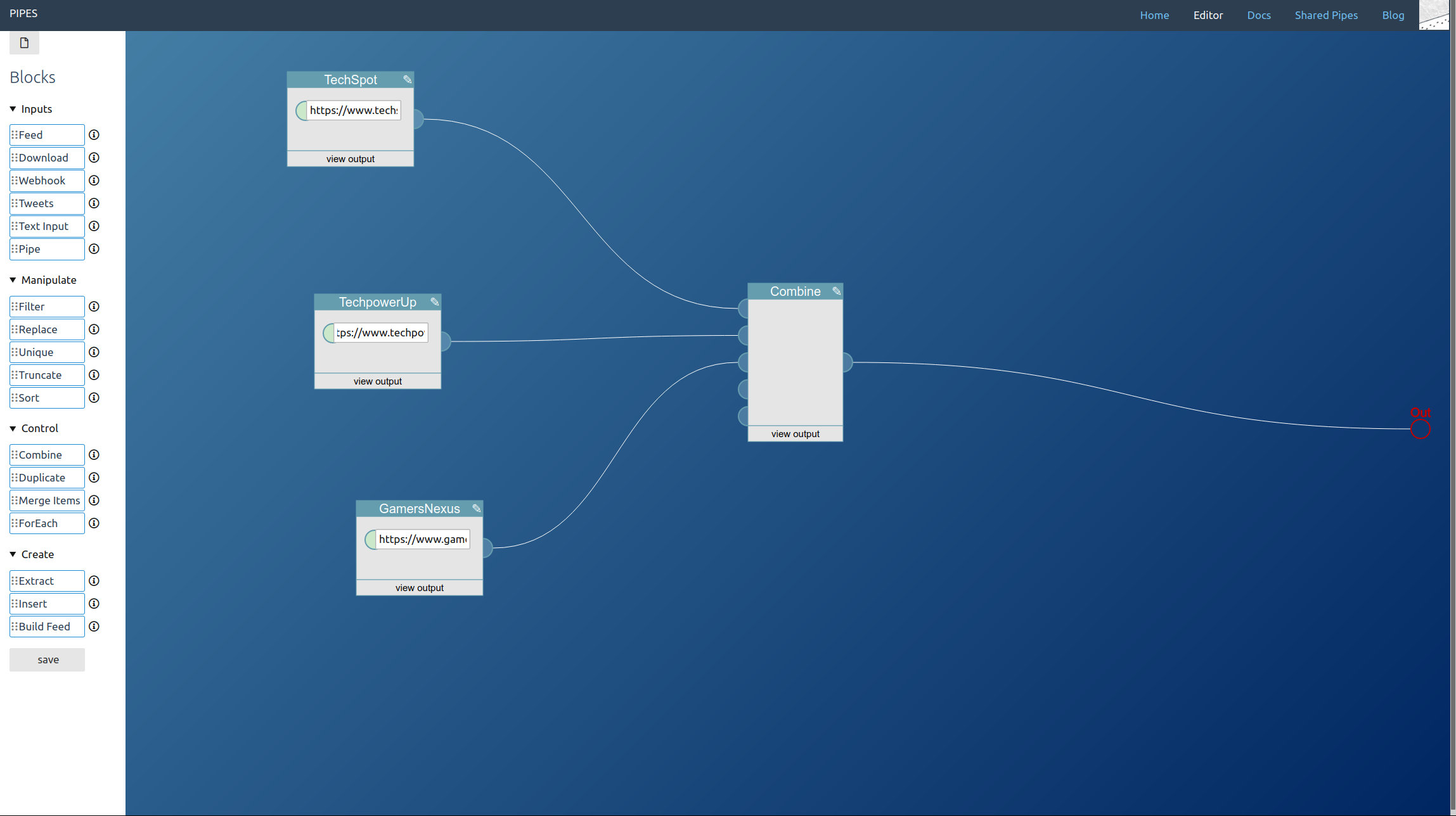
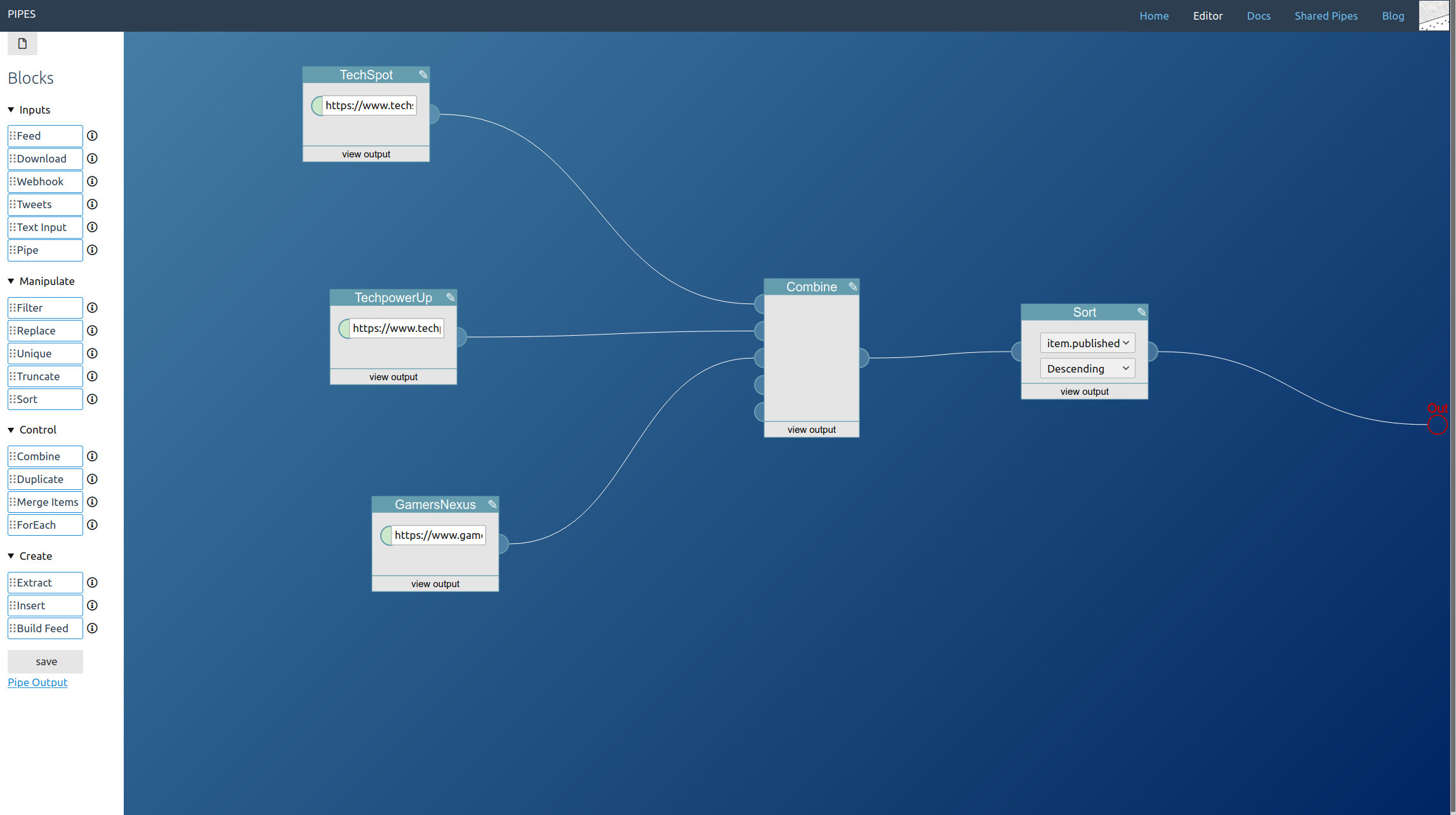
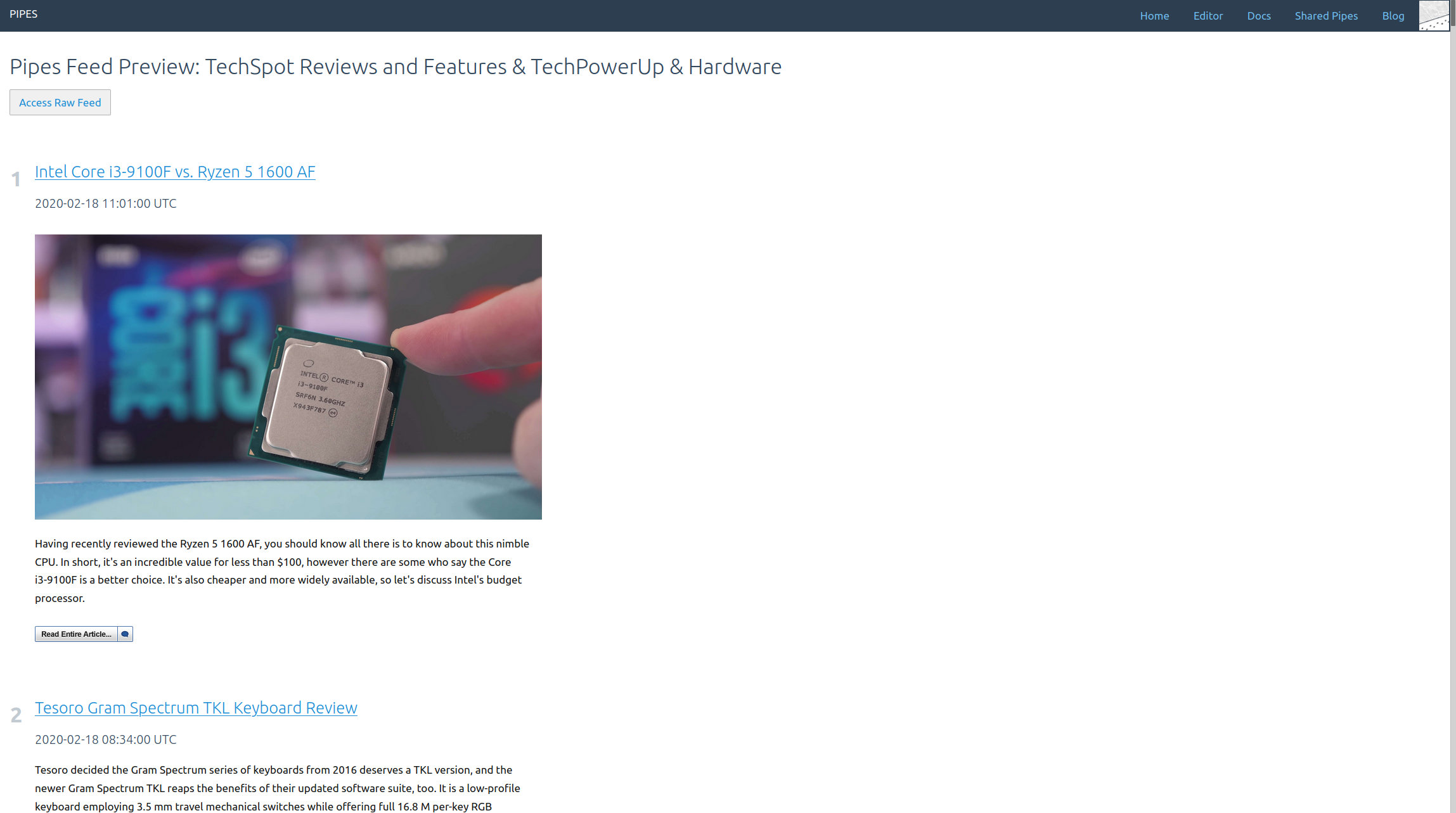
This is part 4 in a series explaining how pipes works and what you can do with it. Read part 1 to learn how to filter feeds, part 2 to see how to combine feeds and part 3 to create feeds for sites that have none.
Some sites prefer not to put the whole article into their RSS feed. For them, having an RSS feed is nice to inform users that new articles are available, but they want you to visit the site, to see the article in the full design, and often to have a chance to show ads. As a reader you might want to respect that. But if not, that’s okay as well. Pipes often can transform such a feed into a full text feed, and here I will show how that works.
The prior article explaining how to create a feed for a site will be useful for this, because that’s basically what we will do to get the full text feed content, but with the original feed as a starting point.
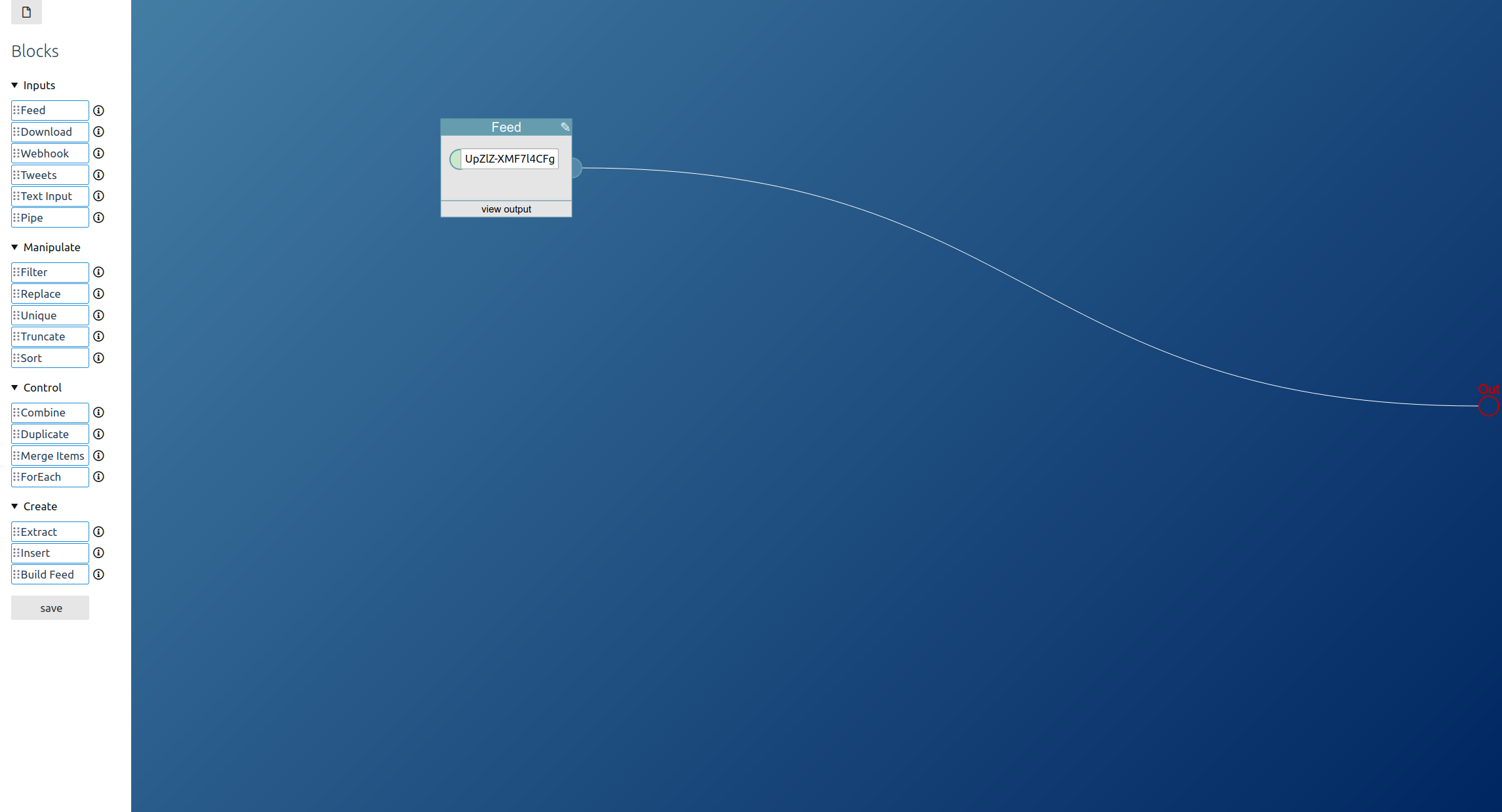
Like always we will first create a new pipe.
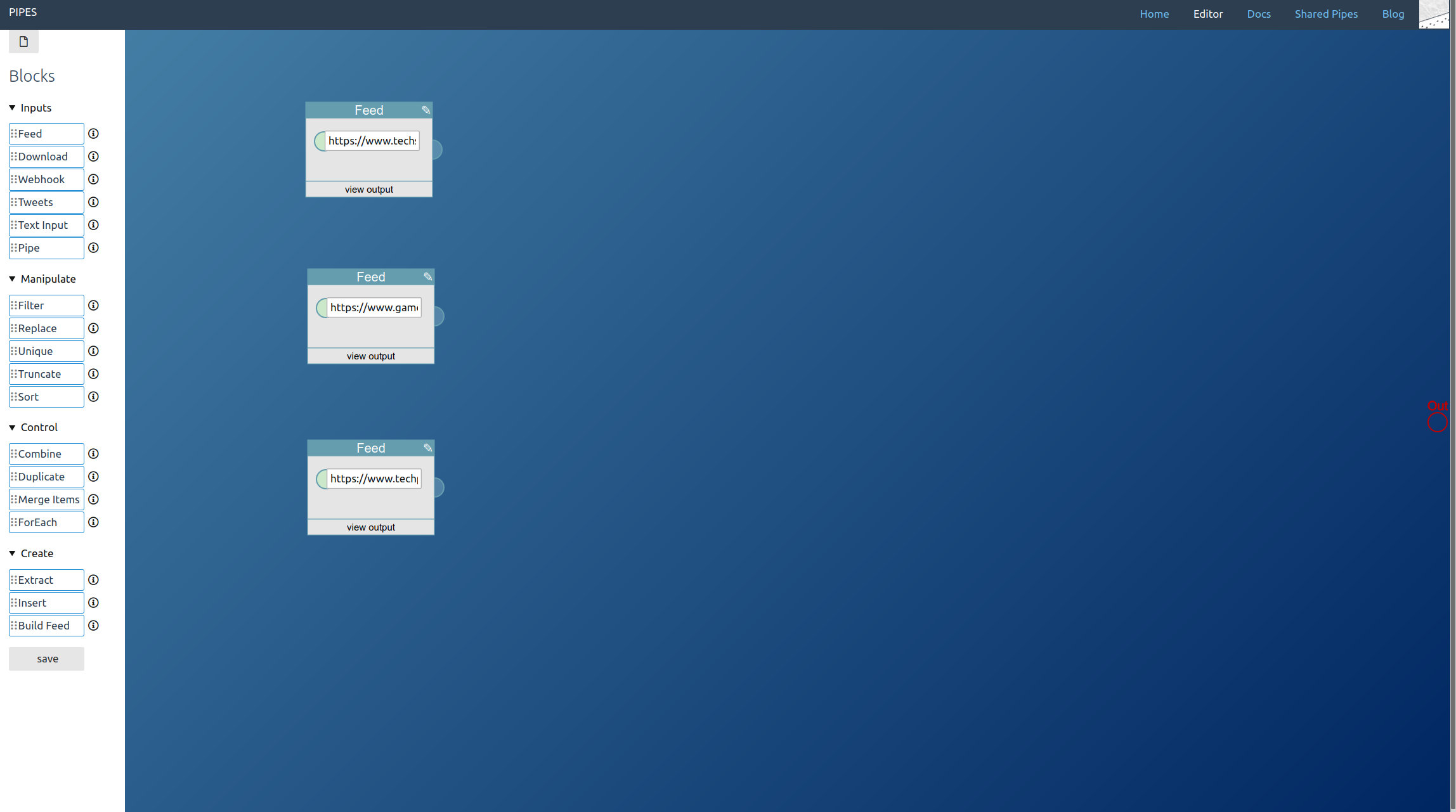
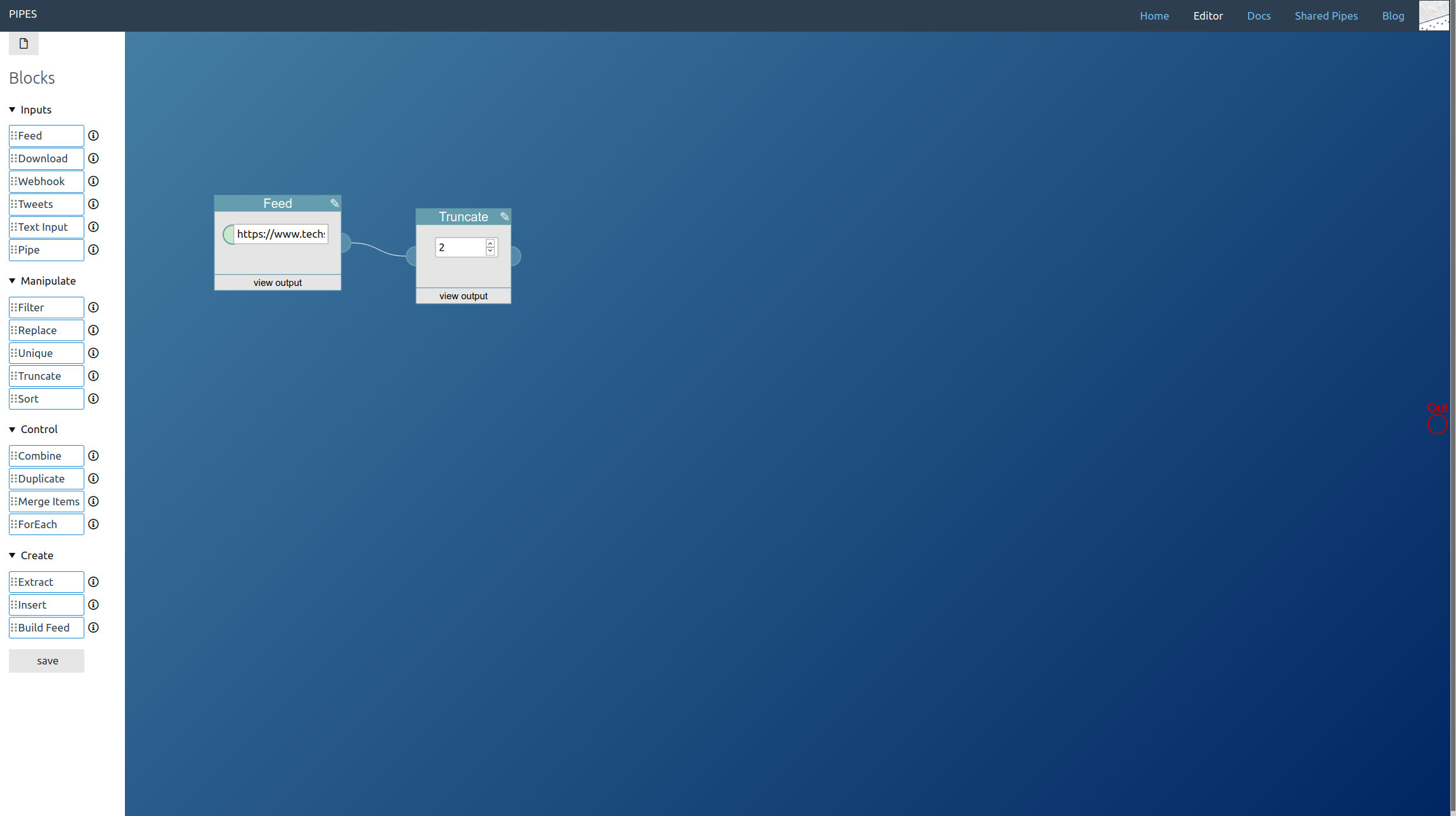
First drag a feed block into the editor area. Enter the feed url. In this example, we will also truncate it to get only the two newest feed items: If we already crawl the site it is only fair to keep the load low. But that’s optional.
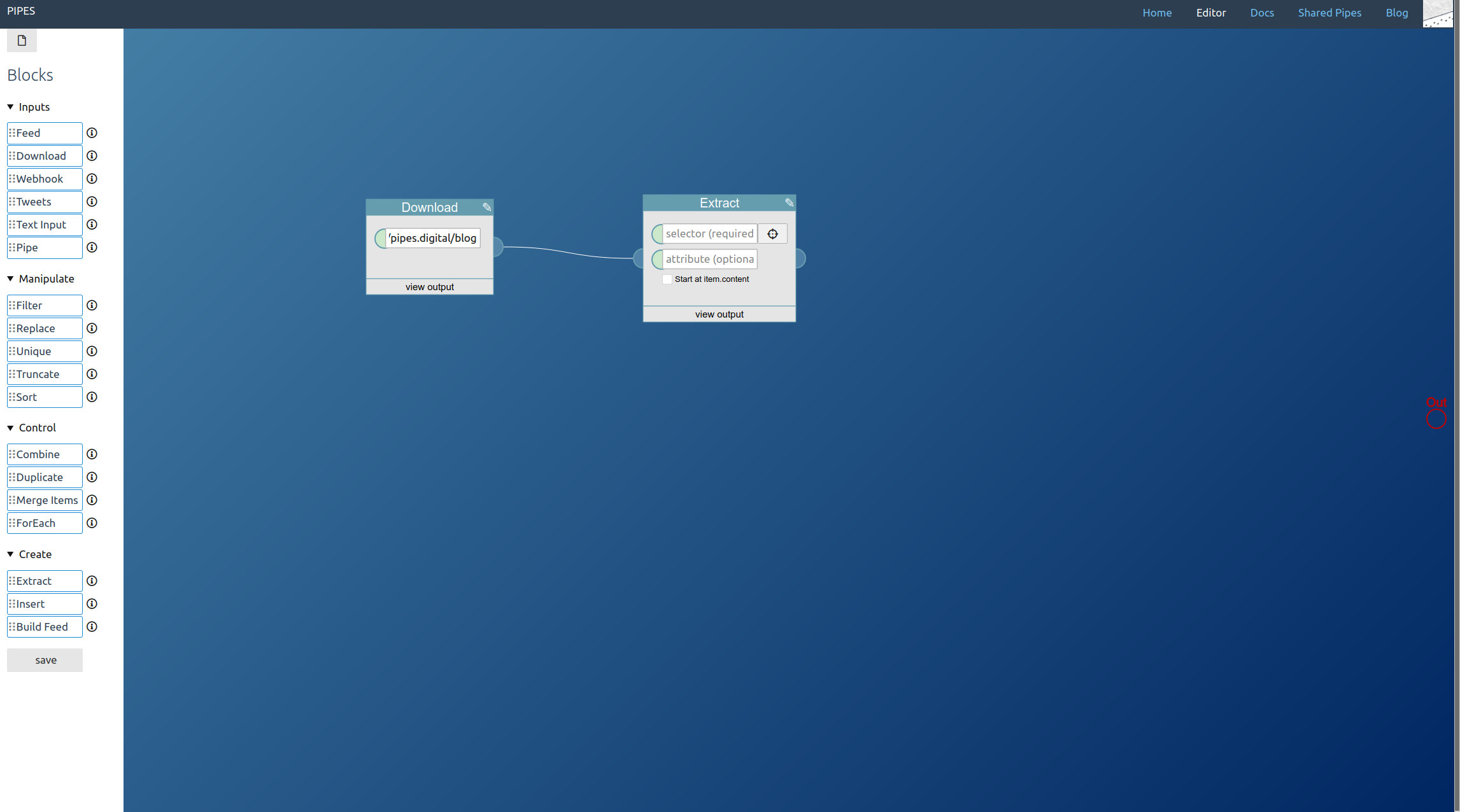
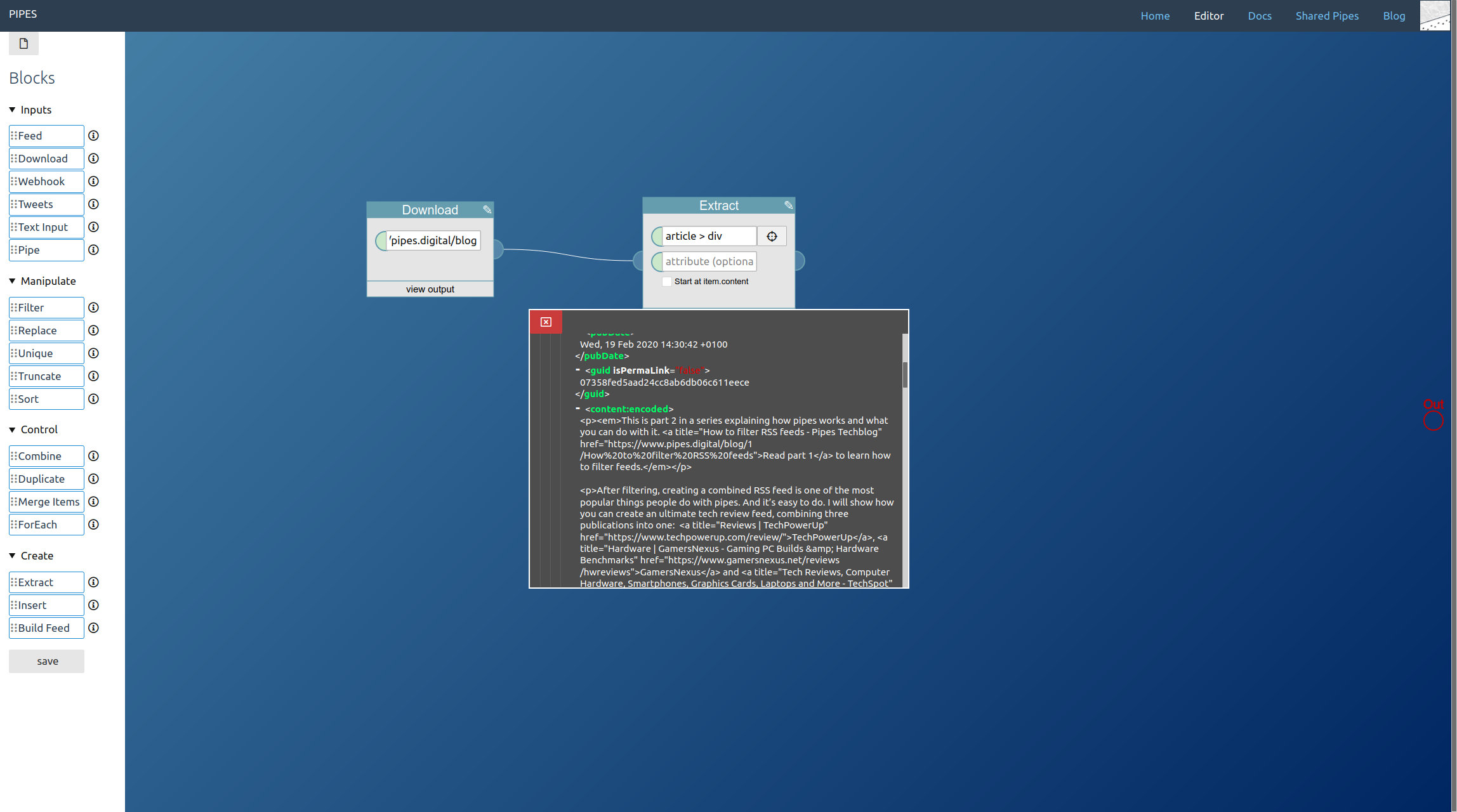
From the shortened feed we need the links to the articles. This time I decided to take them from the guid element, the link element would have worked as well. Use an extract block to get the text stored in those elements:
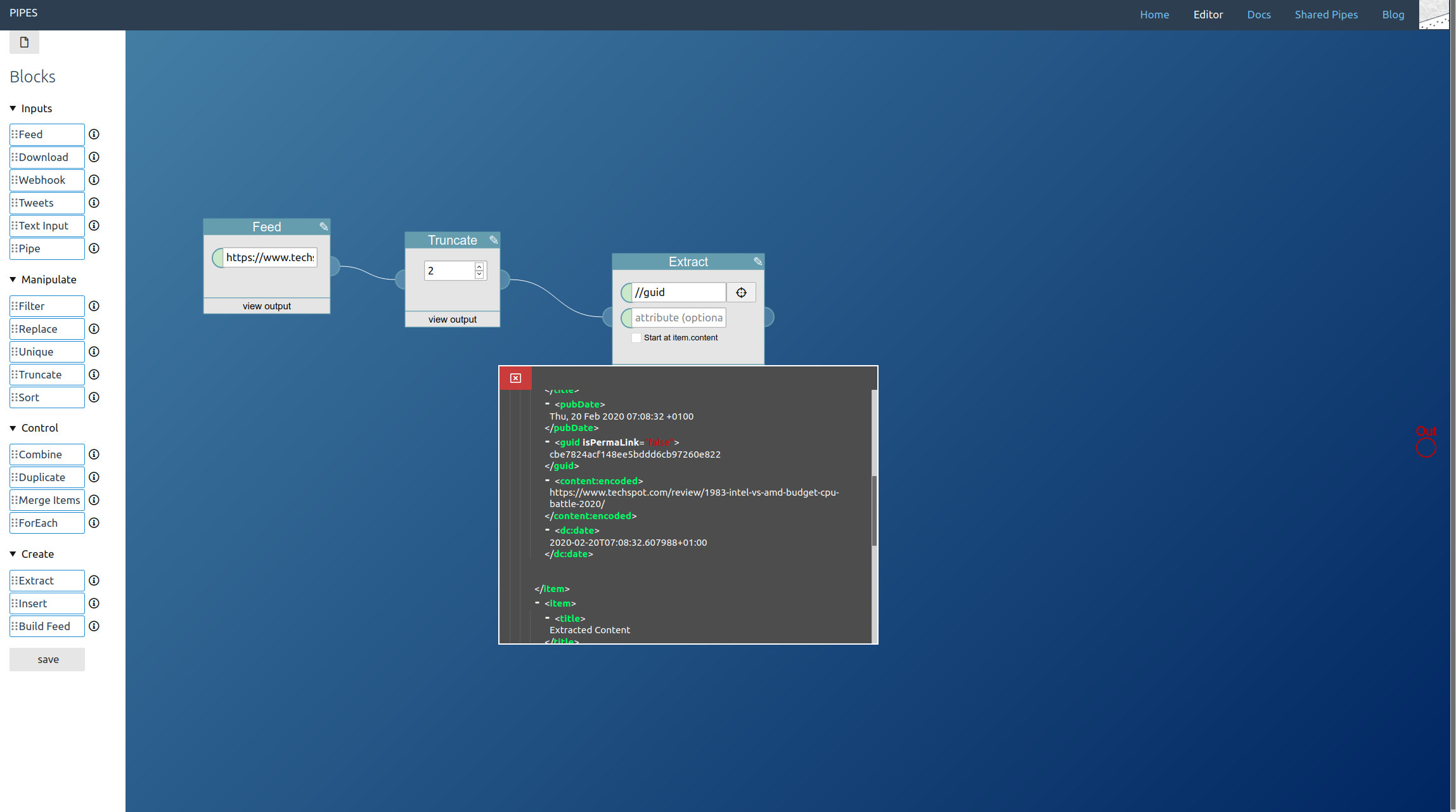
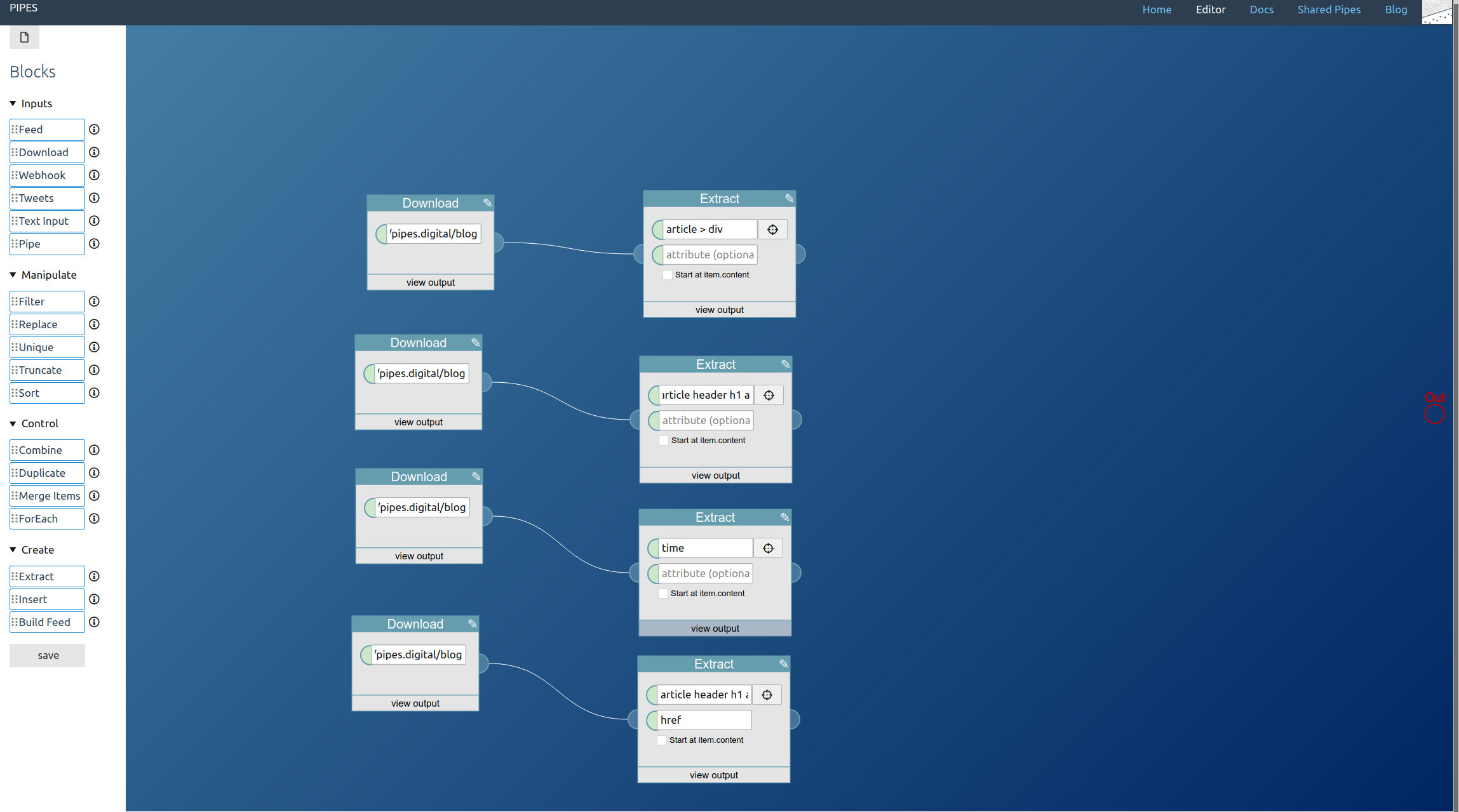
Next comes downloading these articles. But since we have multiple links, we need a foreach block:
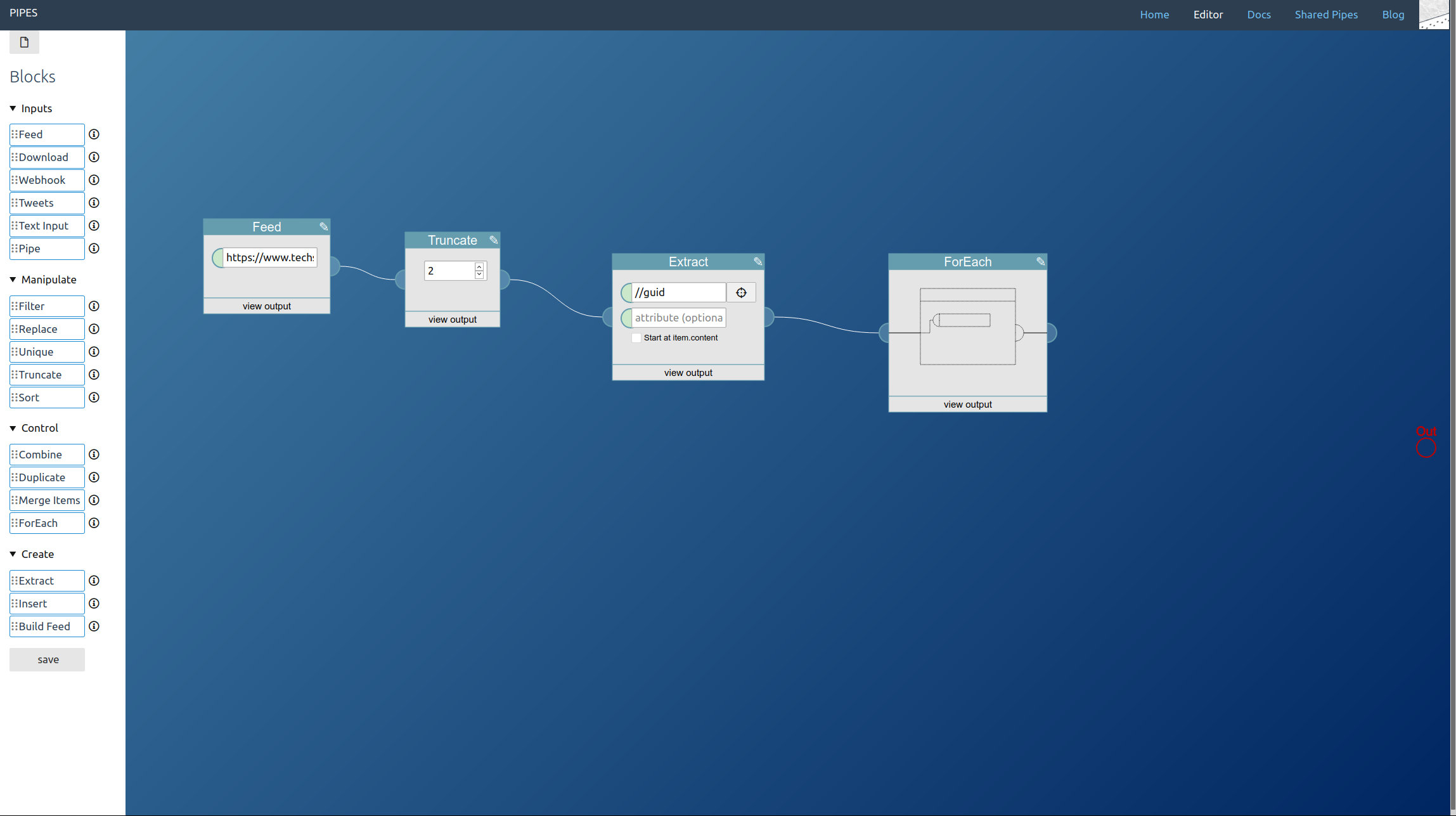
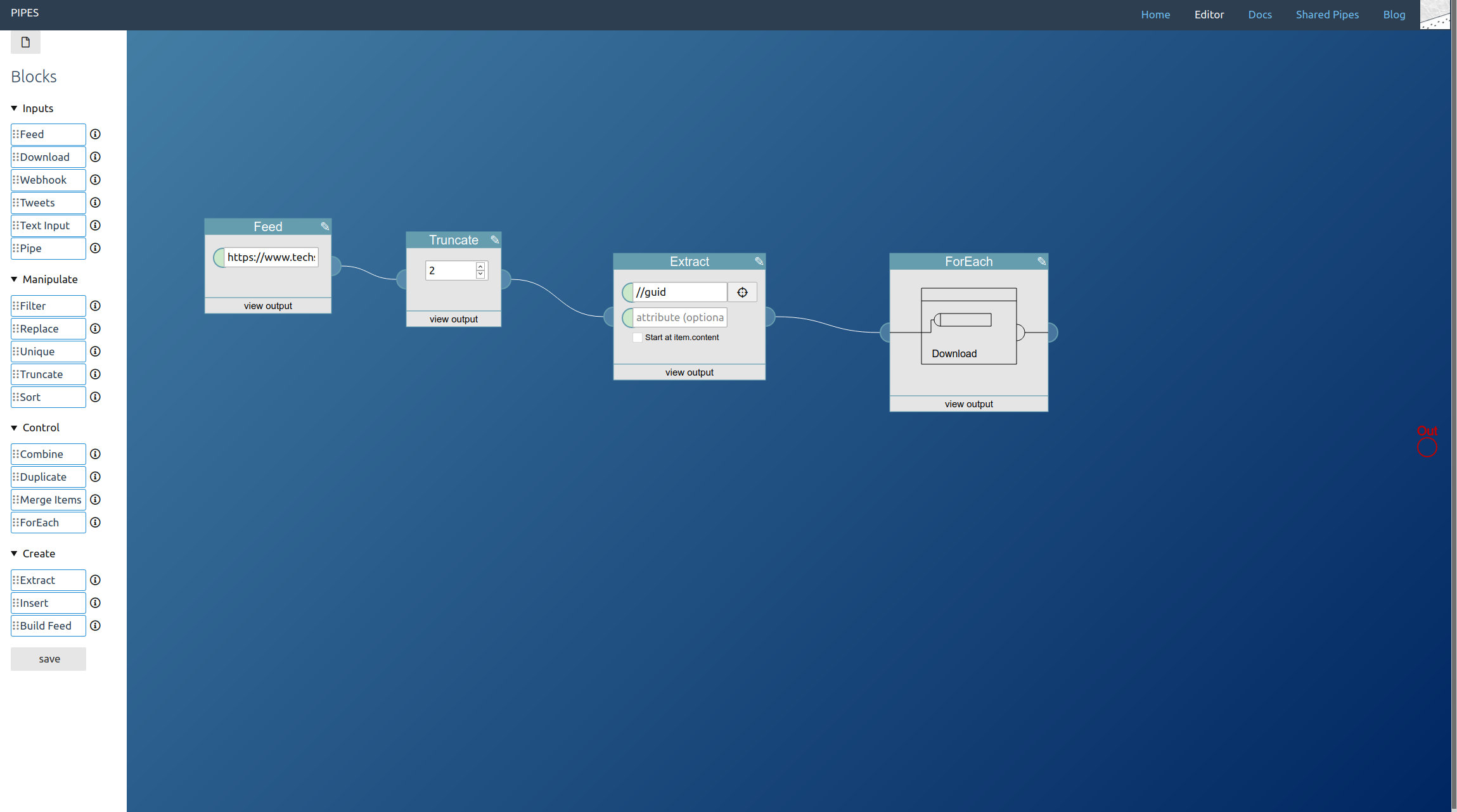
Place it, then add a download block next to it, and then drag the download block onto the foreach block (the foreach block should turn yellow when hovering it with the download block). This means: For each url given to this block, download it:
Since we need multiple elements from the downloaded articles, at this point duplicate the output of the foreach block with a duplicate block:
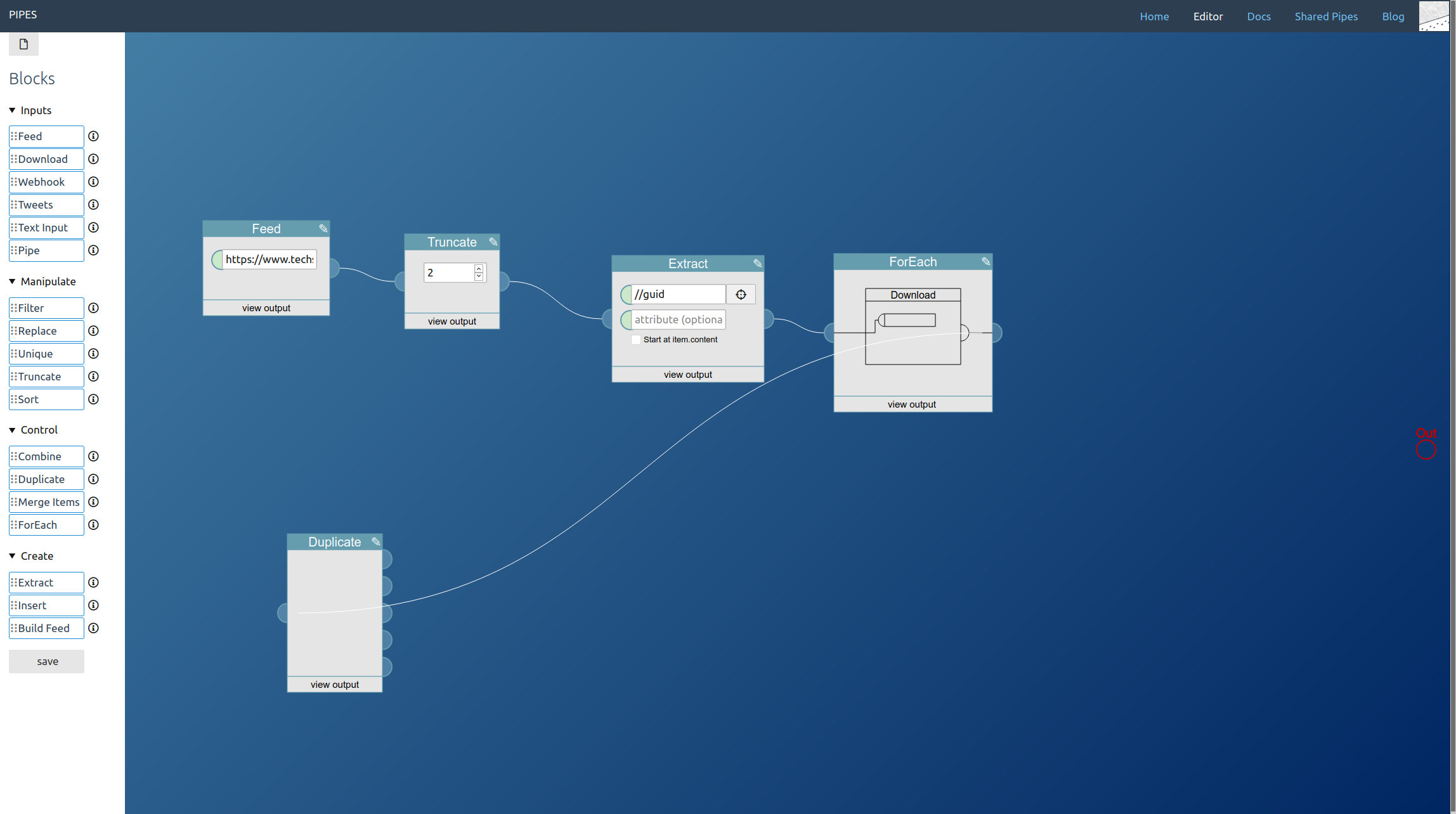
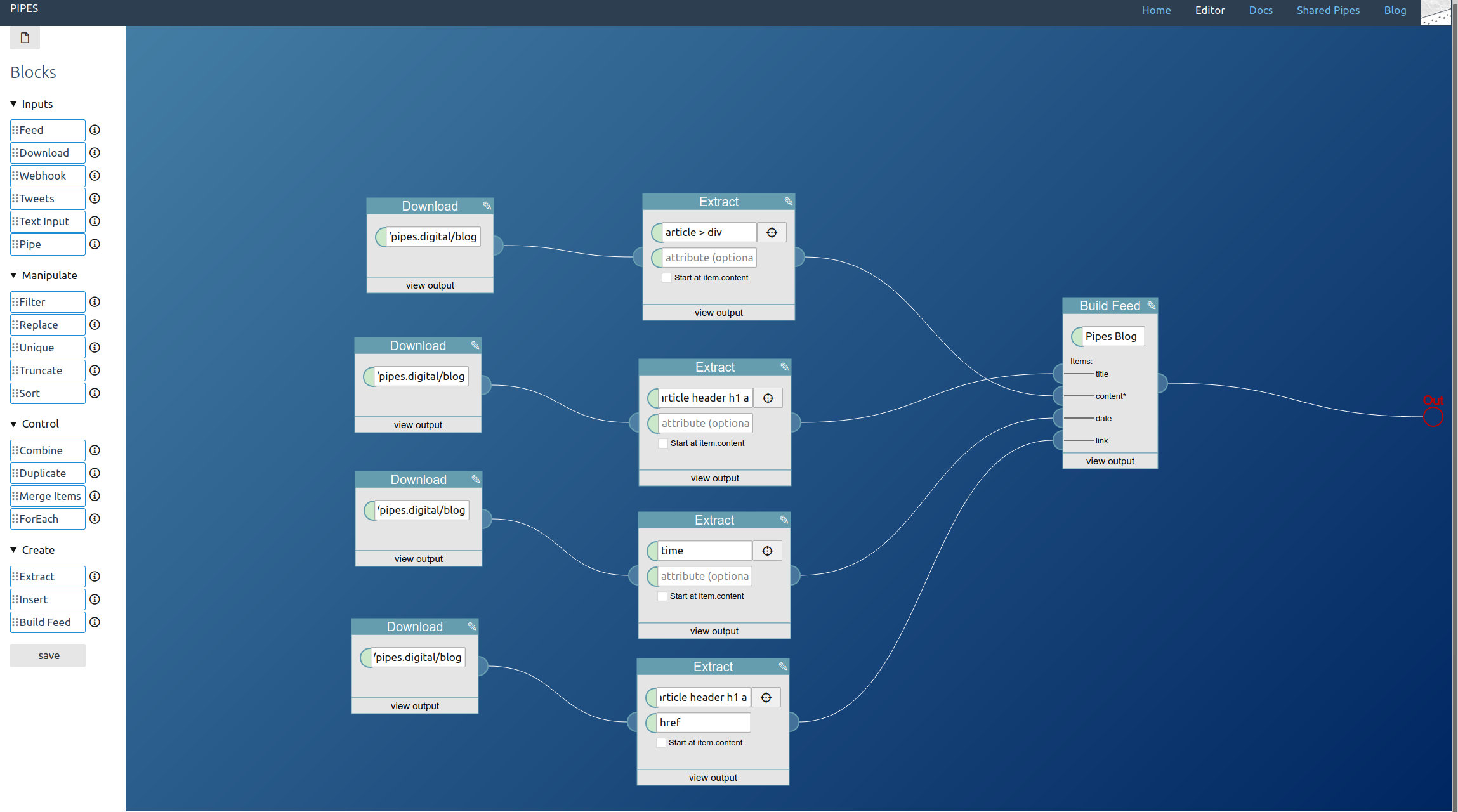
The next step is extracting the elements we need for the full text feed from the article pages. Again it’s the extract block that does the work, and which selectors to pick depends on the HTML structure of site and will vary a lot. But this time, unlike when using a download block on its own, the downloaded site is wrapped inside items of an RSS feed, that’s the output of the foreach block. Thus activate the option Start at item.content on each extract block when entering the CSS selectors. For the example site they look like this:
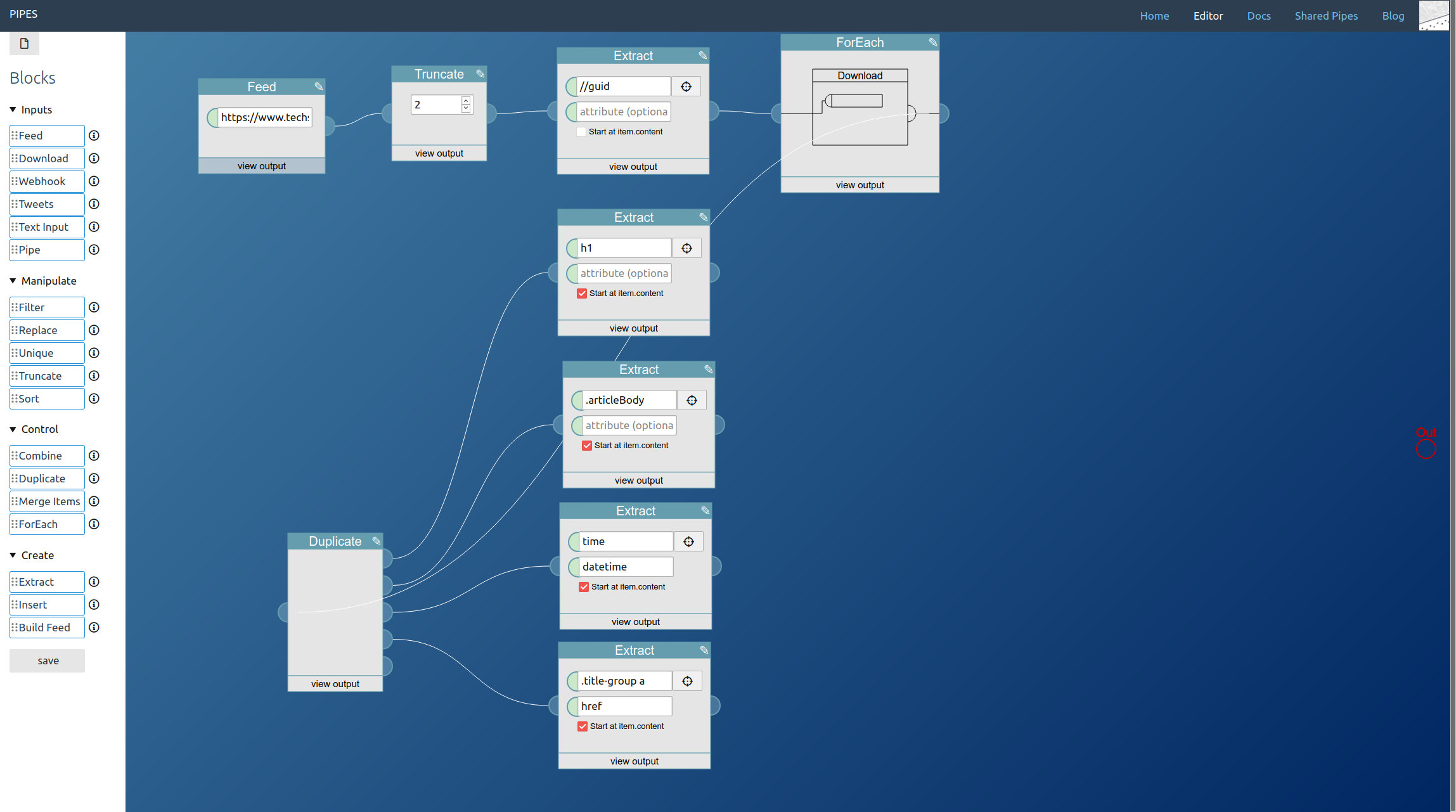
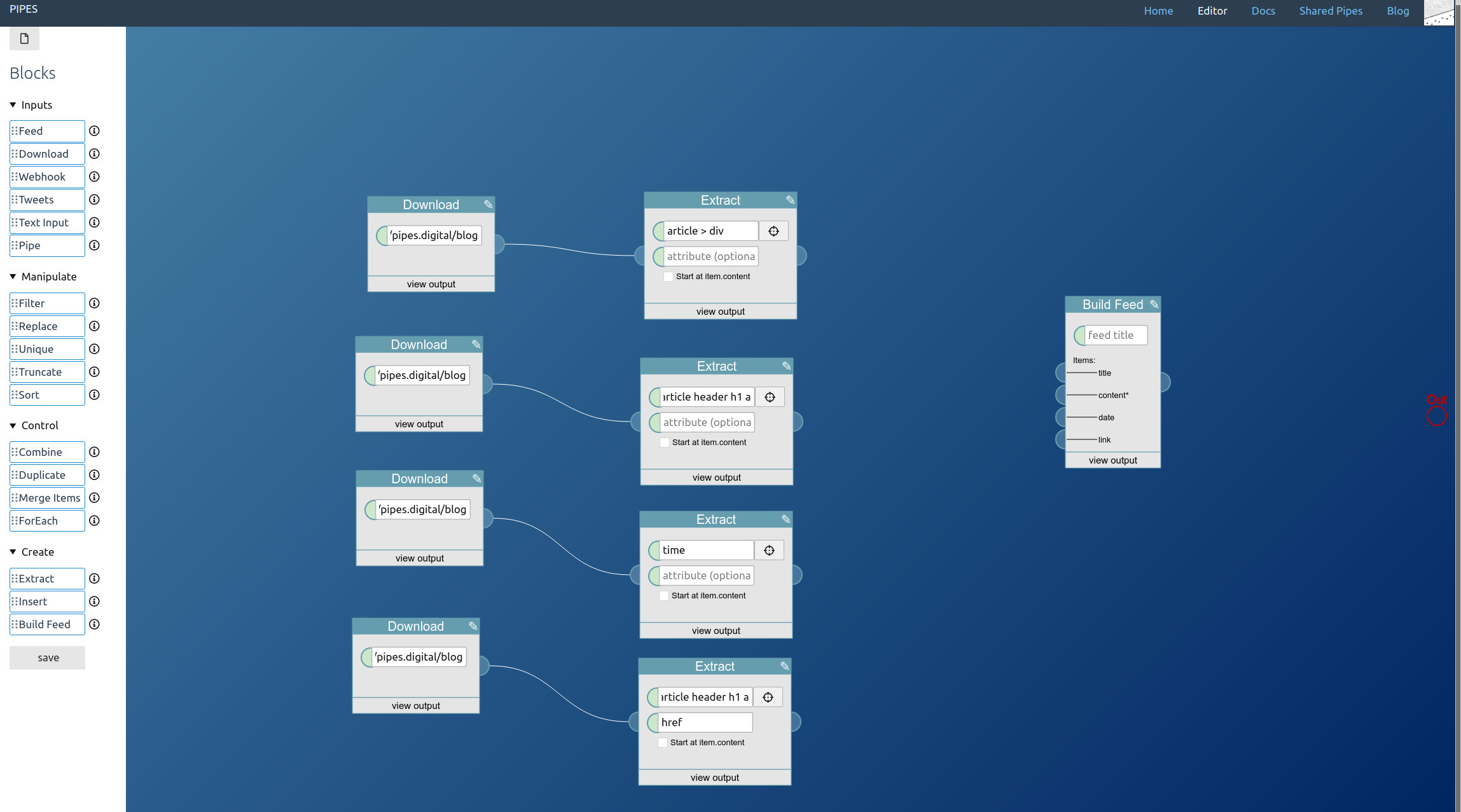
A feed builder block is the only regular part of the pipe missing. Place it near the extract blocks and connect them together, set a title and connect its output to the pipe output at the right (which I forgot to do before taking this screenshot):
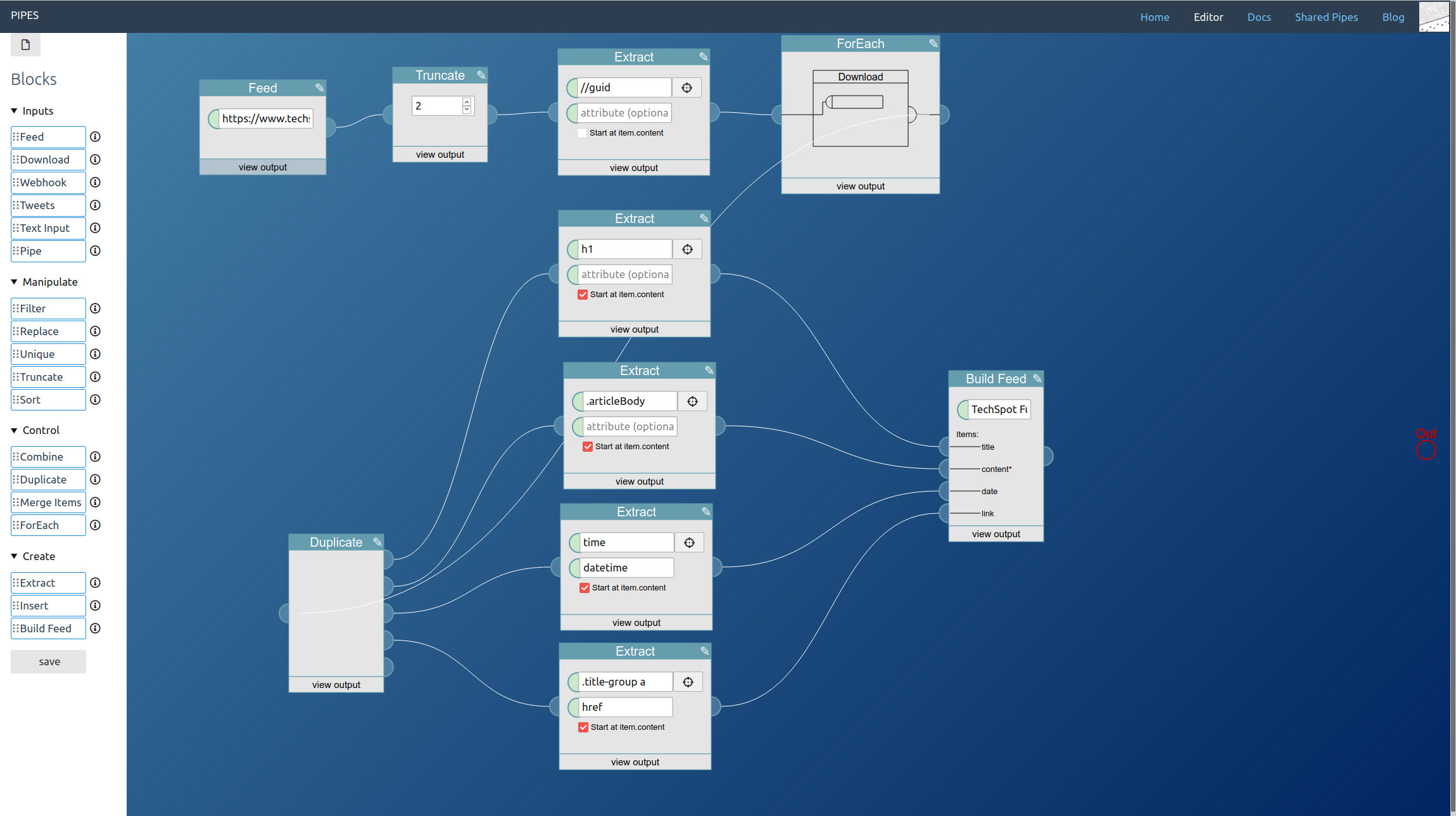
One last thing is not perfect yet: images. Some sites like the example site load them via Javascript only when they become visible. That will not work in a feed since most readers will not execute the Javascript, even if it were inlined into the article text. But we can fix that: The real image link is normally stored in a data element, here it is data-src. With one replace block remove the current src that just has a placeholder, with a second transform data-src to src:
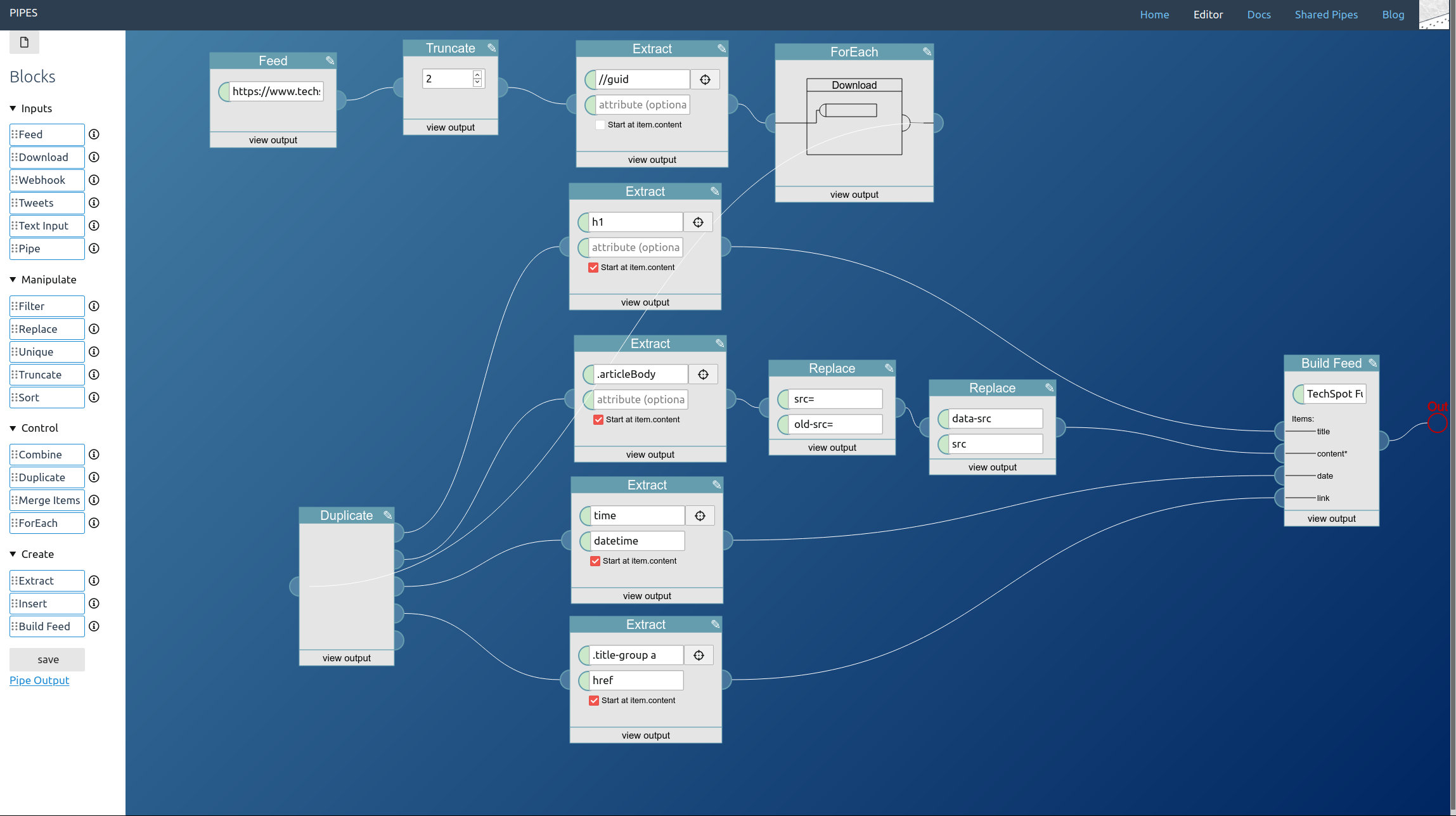
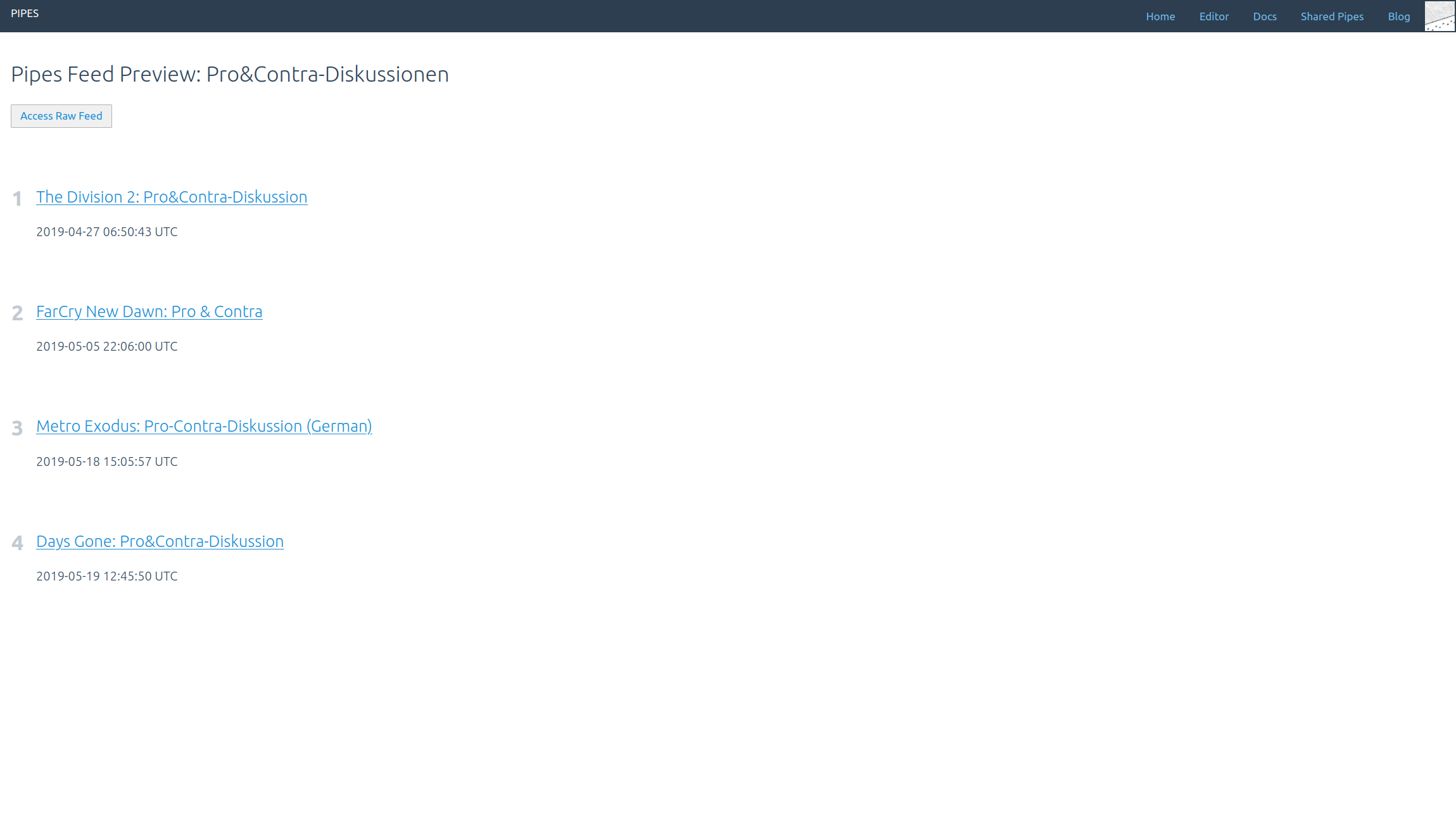
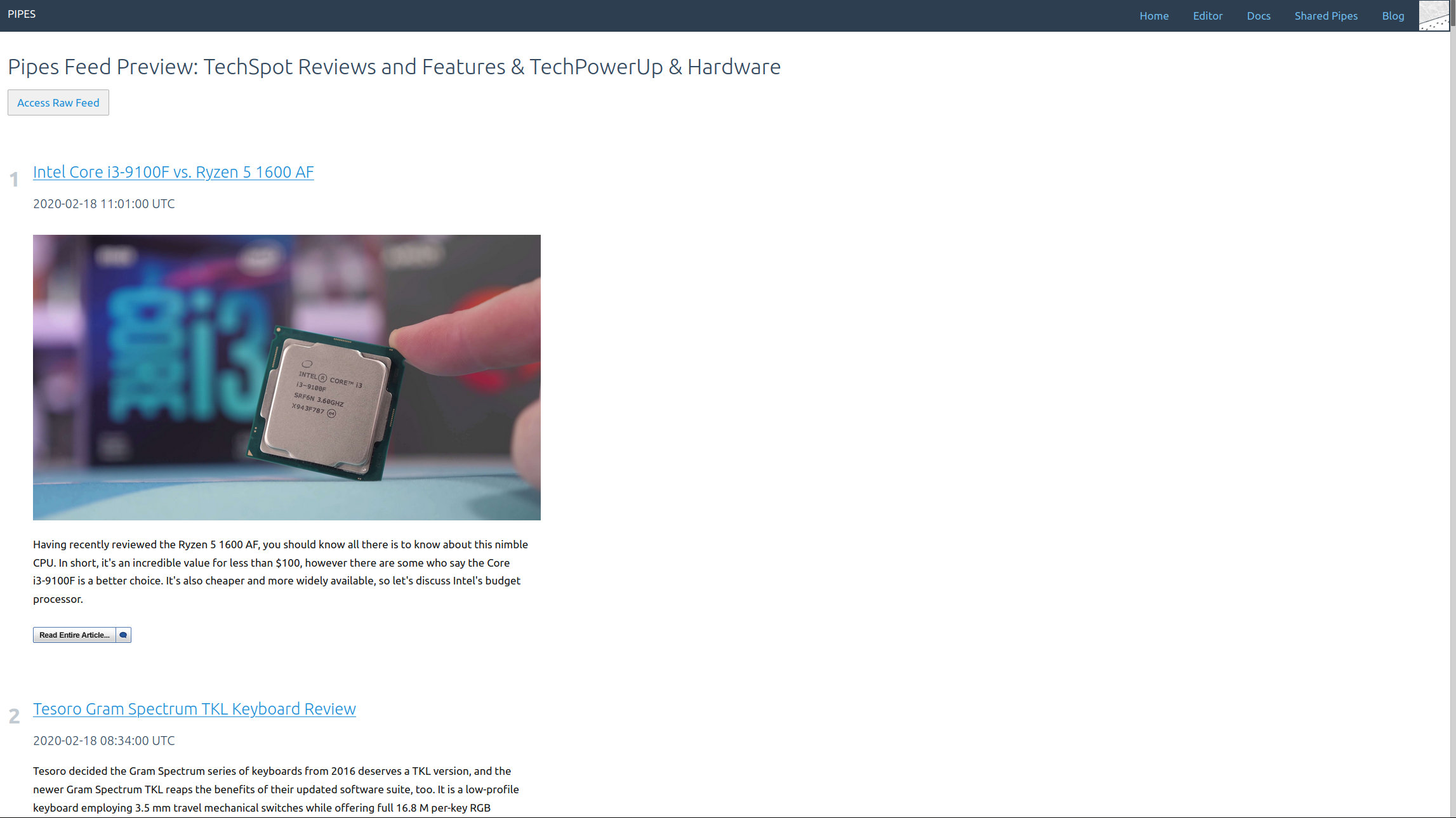
Now the images load. The whole feed looks good:
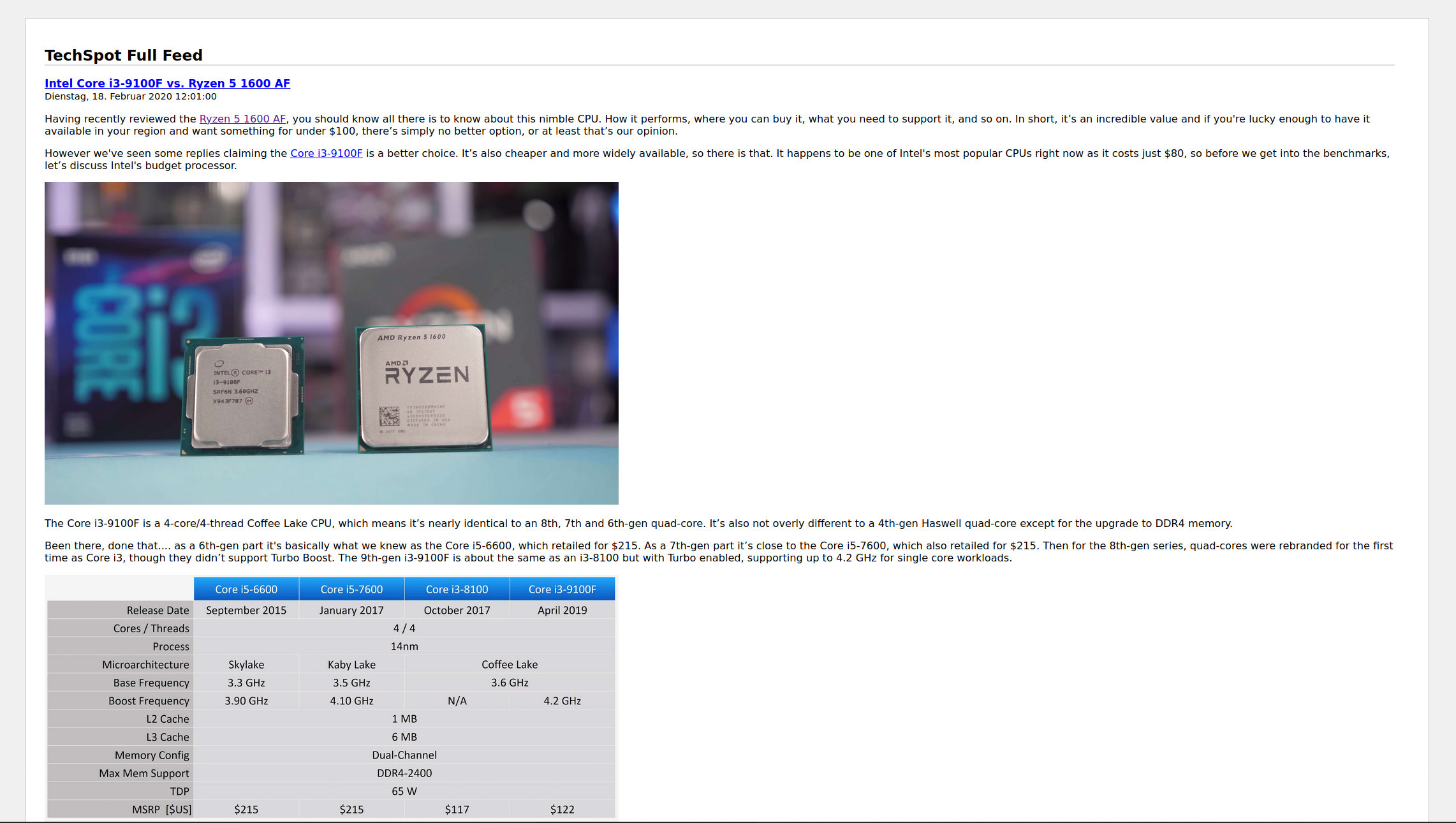
And that’s everything you need to create a full text RSS feed when the site you want to follow just delivers a shortened RSS feed.
You can see the pipe I created for this article here. You can fork it to use it as a starting point to transform the shortened feed of your favorite site into a full text feed.