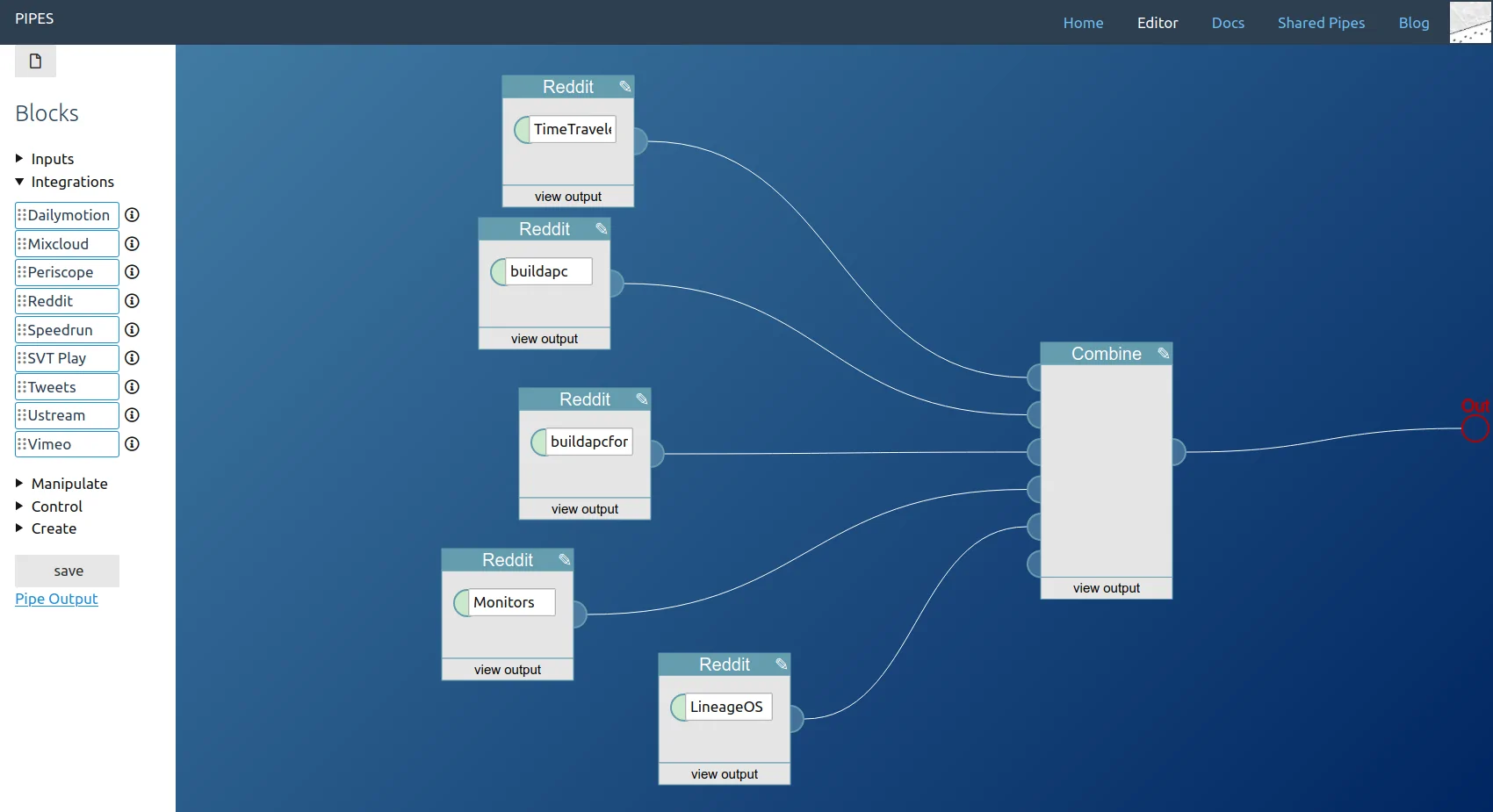
Now that Pipes got an open source release, I’d like to present this dive into the architecture of the software. I hope it will be helpful for anyone trying to build a similar system, and especially for developers wanting to customize Pipes CE.
Software overview
Pipes goal is to provide infrastructure for users to work with data from the internet. It provides a visual interface where data flows from block to block and each block does one operation. Internally, each data item is an item in an RSS feed that gets sent from block object to block object, and also external data input is often an RSS feed, though it is possible to fetch data from webpages and to send XML or JSON data to webhook blocks. A typical example for what users do with Pipes is combining multiple feeds into one, filtering them, or creating feeds for sites that do not provide them. It definitely stands in the tradition of Yahoo! Pipes, hence the name.
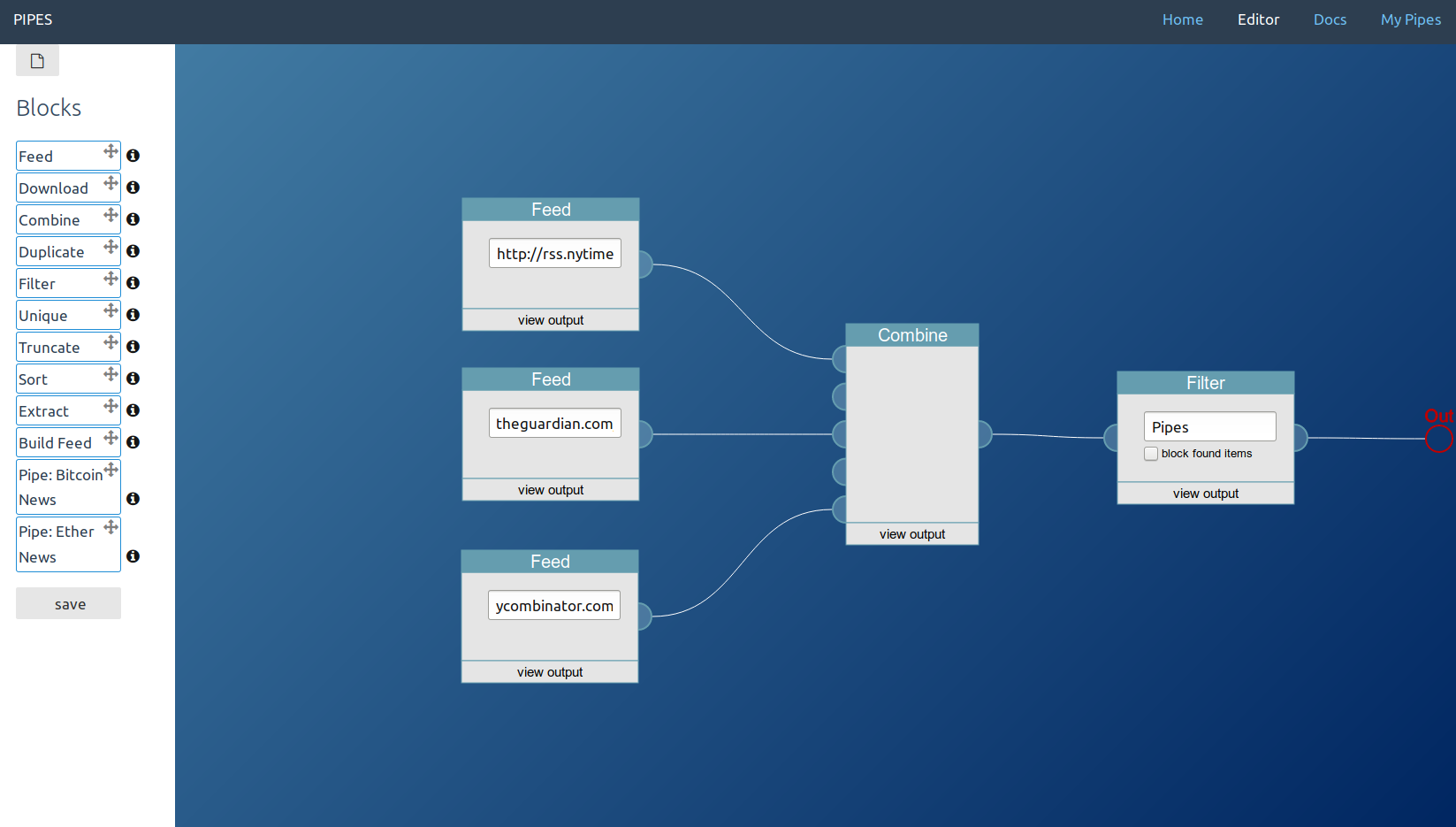
Pipes is a Ruby/Sinatra application, uses SQLite as database engine and Raphaël for the main part of the frontend, the editor. Ruby works well here, since it is a very expressive language with a healthy ecosystem around XML (oga, nokogiri) and some useful modules for RSS/ATOM normalization (feedparser, feedjira), and creation (included). Sinatra provides the webserver parts of the system and the HTML views, this part is rather small. SQLite is the data store for everything, including the pipes serialized to JSON and cache data. And finally Raphaël abstracts creating the SVG part of the javascript powered editor, painting the blocks and manipulating them.
Portier is used as the auth system. It enables logins without having to store passwords. Users log in with their email address and only have to confirm that they control that address, by either clicking on a link sent to them or, for Gmail, logging in with their Google account. That work is done by an external broker, Pipes just has to check the token sent back by that system.
Backend
I will start with a description of the backend, because defining the data structure is also how Pipes started.
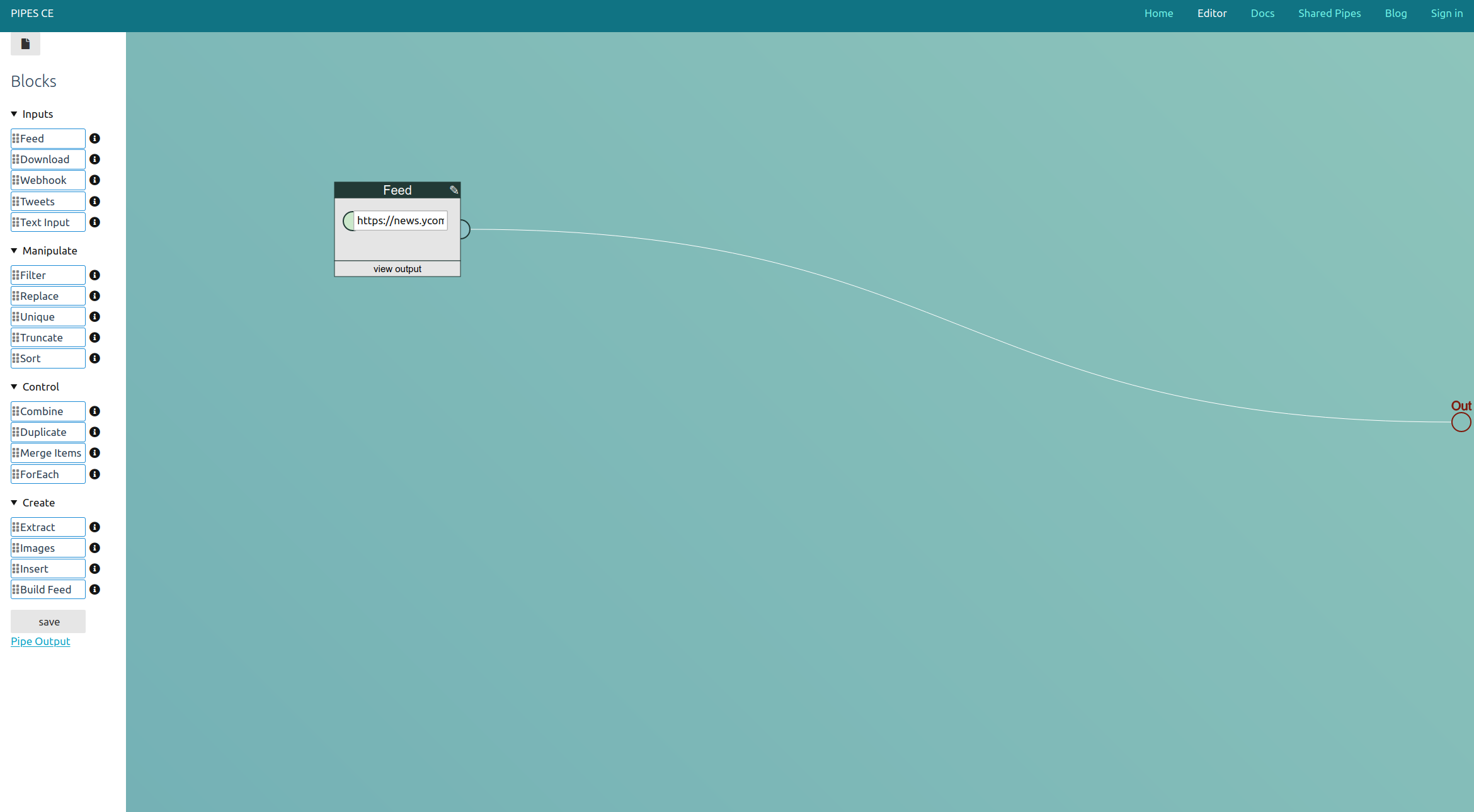
It began with the realization that a pipe can be thought of as a tree. The pipe’s output object is the root of the tree, the block that connects to its input are its children, and so on, until you reach the blocks that have no inputs, the leaves. That will usually be a Feed or a Download block, though that later expanded to also allow other Pipes (as represented by one block), Twitter or the Webhook block. Running a pipe means asking the root object of the tree for output, which will ask its children for input, which iterates through the whole tree until blocks that provide input are encountered. This data then flows back through the tree up to the Output block, with each block doing its own operations on the transported data.
So when you look at this pipe, where two Feed blocks fetch some data, one is filtered, then both are combined into one feed and that combined feed set as pipes output:
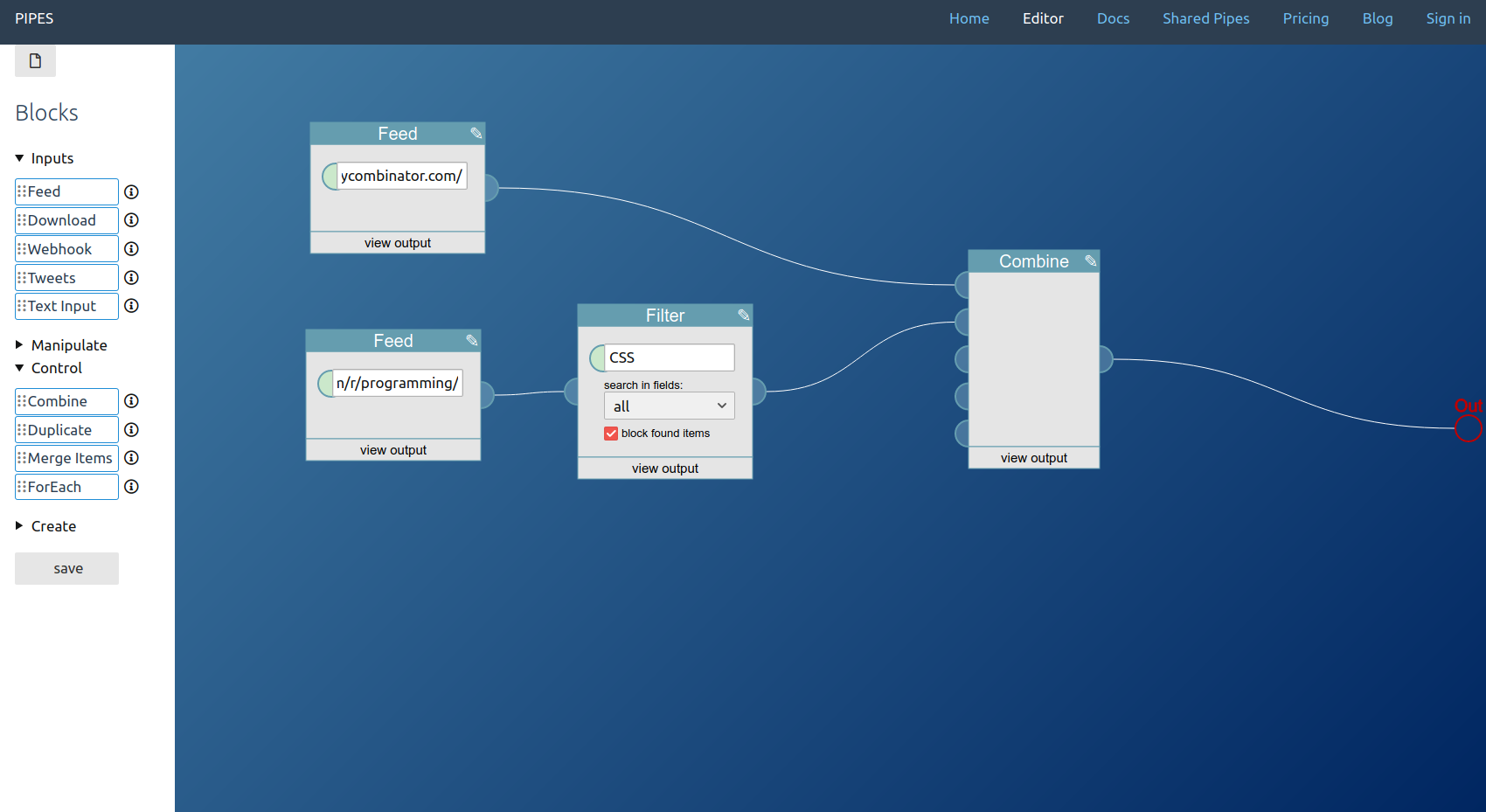
You are actually looking at this execution tree:

The code that enables this structure is minimal. There is a Pipe object, defined in pipe.rb. There is also an abstract Block object, defined in block.rb, the parent class for all blocks. Those two classes together define the pipe execution flow. An instantiated subclass of Block has an array of inputs, containing other blocks. When the system runs a stored pipe, this happens:
- A
Pipe object is created
- That object fetches the JSON structure as stored in the database and sets the output block as its
root
- Then it creates the block objects that are the inputs of the current block, by recursively calling
createInputs on its children and their children.
- To finally get the output, it calls
Pipe.run(), which calls Block.run(), which will go through the tree as described above.
- The actual data manipulation work is done in a
process function each indiviudal block has to define on its own. Look for example at the process function of the FilterBlock.
To define pipe execution like that has a hidden advantage: When you want to see the output of a pipe at a specific node of the tree, at one specific block, all you have to do is set that block as the root element of a new Pipe.
This describes almost all classes and files of the backend. Additionally, there is a server.rb, the entrypoint for the Sinatra application and where all routes as well as some helper functions are defined. twitterclient.rb is a small wrapper around the twitter gem and used by the twitter block. downloader.rb is central for most pipes, as it is used by the Feeds and the Download block to fetch data, and the central cache is set here that prevents requesting data from other servers too often. The Gemfile describes the requirements, the config.ru makes the application runnable by the usual ruby commands and also initializes the Moneta session store, that prevents users from being logged out when the server process restarts. HTML templates are stored under views/, ERB is used for them. The individual blocks are stored under blocks/. Images, Javascript, CSS etc are in public/, accessible to users.
As you probably noted, this is all bundled into one application. The way a pipe works, it would be easy enough to divide the Sinatra part of the application and the Pipes part, into what could also be called server frontend and worker backend. That would provide a way to scale horizontally, over multiple processes and even multiple servers. So far this just has not been necessary, upgrading the server has been enough to keep pipes.digital running. But keep that option in mind if you run into performance limitations in deployments with a big amount of individual pipes.
Frontend
The website uses server side rendering, as provided by Sinatra. But that describes only the starting point and the less important parts of the frontend adequately. The heart is the editor that gets initialized by a HTML template (views/editor.erb), but then fetches and sends data via AJAX, more akin to a Single Page Application. It is a big SVG canvas powered by Raphaël, with absolutely positioned HTML input elements mixed into it, to make the blocks configurable. Its code lives in public/pipes-ui.js.
The main objects here are blocks and connectors. Connectors can be Inputs or Outputs, and there exist TextInputs and TextOutputs for the text fields that double as parameters when calling a pipe. Let’s look at the Filter block as an example.
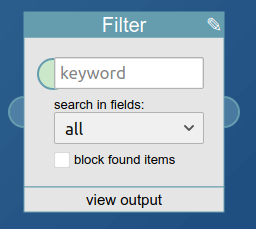
In simplified form it is defined like this:
function FilterBlock(x, y) {
Block.call(this, 1, 1, x, y, 'Filter', 200, 150);
this.userinputs[0].style.width = '150px';
this.userinputs[0].required = true;
this.userinputs[0].placeholder = 'keyword';
var textinput = new TextInput(x + 29, y + 37, this);
this.textinputs.push(textinput);
var field = document.createElement('select');
var all = document.createElement('option');
all.value = 'all';
all.text = 'all';
var content = document.createElement('option');
content.value = 'content';
content.text = 'item.content';
field.appendChild(all);
field.appendChild(content);
field.style.position = 'absolute';
field.setAttribute('data-xoffset', 30);
field.setAttribute('data-yoffset', 75);
field.style.left = x + 30 + 'px';
field.style.top = y + 75 + 'px';
field.style.width = '150px';
field.name = 'field';
document.querySelector('#program').appendChild(field);
this.userinputs.push(field)
}
What happens here? First, Block.call creates a Block object. The constructor of the Block object (that’s just the function Block) creates the needed SVG elements. The two 1s define the number of Inputs and Outputs the block will have, x and y are the position on the canvas, 'Filter' the title as shown in the title bar of the block, and finally the width and height are set to 200 and 150.
The Block constructor also creates a userinputs array and adds one HTML input element to it, a text box. That array is where all the inputs of a block have to be stored. That way, other code like the drag’n drop handlers know which absolutely positioned inputs belong to which block. This first userinput element is then changed, a width is set, it is marked as required and it gets a placeholder.
Next, it also gets a TextInput, allowing connections to TextBlocks. That’s the green circle at the left of the text input shown above.
The code that follows shows how to add additional userinput elements, in this case a HTML select element with two options. Note how elements like this are added to the DOM (since they are absolutely positioned and regular HTML elements) and also to the userinputs array, for the link to the block.
Not shown here but working similar to the userinputs and textinputs arrays is the deco array that does the same thing for Raphaël SVG elements, used for example to add text and lines to blocks.
Other main classes, but something you probably won’t need to change, is Connector, the parent of Input and Output, the half-circles at the left and right of input blocks. They manage the block connections.
When a pipe is saved these steps happen:
- The function
save() is called.
- It calls
serialize()
serialize iterates through the blocks array and creates a JSON representation of their current state, including which blocks they connect to- This JSON array gets sent to the backend
While I’m happy with the resulting user interface, this approach to building it involves a lot of manual coding work and is not modern. It would be quite interesting to see an implementation of this interface based for example on Vue, as long as it involves no javascript build process. Not bloating the development process with such an abomination was a high priority goal when starting the project.
Database
SQLite is used to store all data in a file. The file database.rb creates all tables and the functions for accessing them.
Important for understanding how Pipes works are only two: users and pipes. Let’s look at users first:
CREATE TABLE IF NOT EXISTS users(
id INTEGER PRIMARY KEY AUTOINCREMENT,
email TEXT UNIQUE
);
Every user get its own id and a field for the email address. Note how that address is not the id, to make it easier to change it later.
The data for each pipe is stored in the second table:
CREATE TABLE IF NOT EXISTS pipes(
id INTEGER PRIMARY KEY AUTOINCREMENT,
pipe TEXT,
title TEXT,
description TEXT,
user INTEGER,
preview TEXT,
public BOOLEAN DEFAULT 0,
publicdate INTEGER DEFAULT 0,
date INTEGER DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY(user) REFERENCES users(id)
);
The purpose of most of these fields should be clear. Each pipe gets its own id, can have a title and a description and is linked to a user id. For shared pipes public is set to 1. Most important is the pipe column. It contains a JSON representation of a pipe, as created in the frontend when serializing the editor content. That JSON structure is later transformed into the tree, as described above.
Outlook: Open development questions
The above describes Pipes as it is today. But how could future development look like?
Much of the development so far was user driven. Exchanges by email or in the issue tracker lead to improvements, big and small, like being able to run javascript before crawling sites, create CSS selector for fetching data from sites by clicking on the target elements in an overlay, or keeping media enclosures. I’m sure more will follow, but that development is unpredictable to me.
One thought I return to quite often is the focus on RSS feeds. Right now, that is baked hard into the software, as the data exchange format between blocks. That plus normalization is a big part of what makes the current approach as powerful as it is. But I often wonder whether there could be a better approach, something that still allows manipulating RSS feeds and creating them as pipe output, but making it more straightforward to work with raw text, XML, JSON or other structured data instead. That was also the starting point of the usecase focused blog series describing how Pipes can be used today. Finding a better concept could allow supporting more usecases (how would they look like?) and also remove the need for normalizing RSS/ATOM/JSON-Feeds before manipulating them, which could become an optional step of the feed block. One advantage there would be avoiding the issue of sometimes removing parts of the original feed not covered by that normalization.
Splitting the backend into a server part and a multiprocess program running the pipes would be an optimization useful for big deployments. It could also be nice when deploying to multicore servers with weak cores, like those ARM servers scaleway used to offer or a Raspberry Pi at home. Resque could work well for that.
Porting the user interface to a more modern javascript library could be worthwhile if it would result in new capabilities for the user, maybe even supporting new usecases that way.
Questions, suggestions? Join the pipes gitter channel or open a github issue.