This is part 5 in a series explaining how pipes works and what you can do with it. Read part 1 to learn how to filter feeds, part 2 to see how to combine feeds, part 3 to create feeds for sites that have none and part 4 to convert a shortened feed to a full text RSS feed.
Maybe you do not want to read tweets on Twitter, or you want to embed a bunch of them somewhere else. It might be useful to access them as an RSS feed, and in the process be able to sort and combine them into one bigger feed. That’s something pipes can help you with.
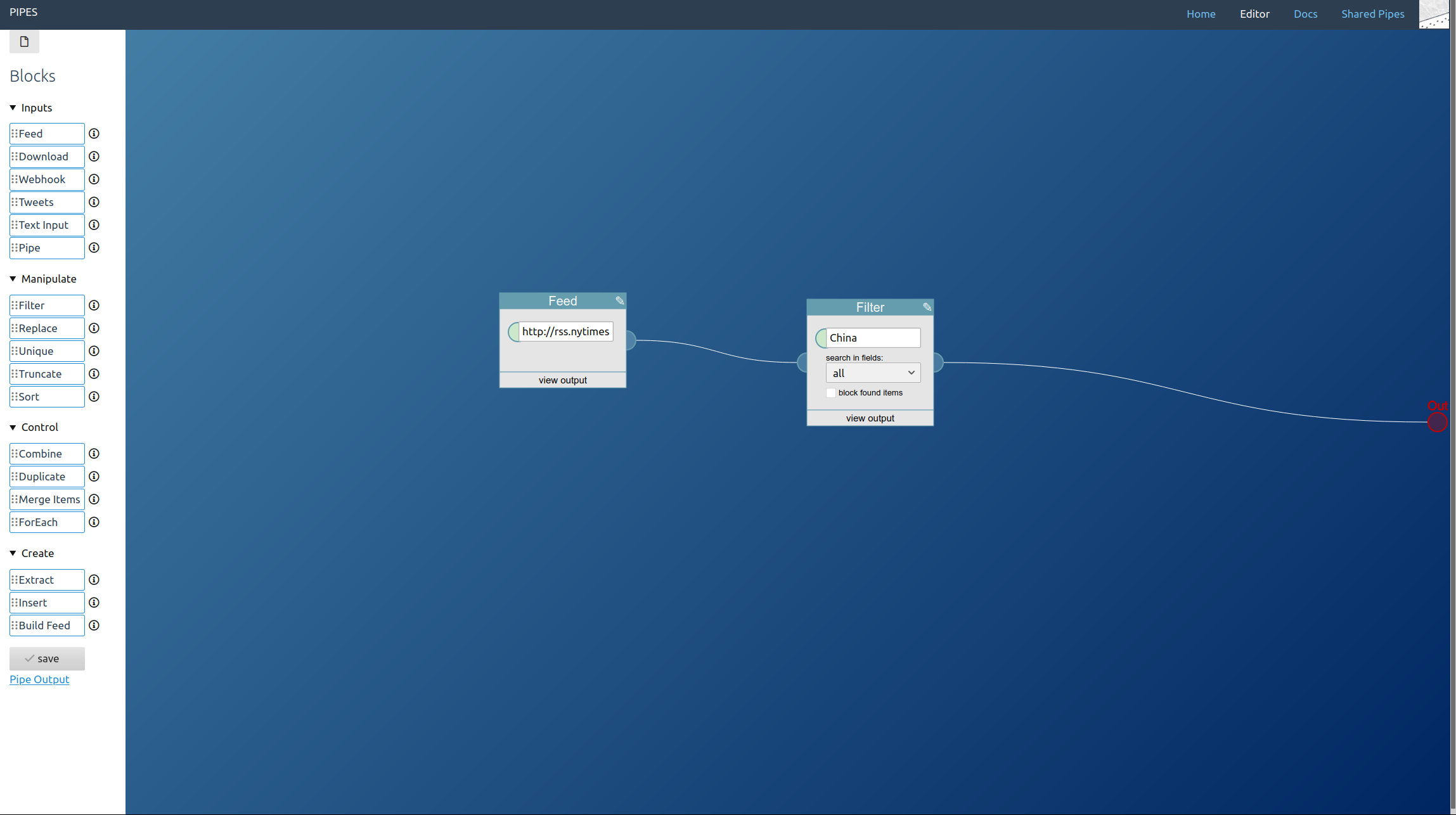
Like always we will first create a new pipe.
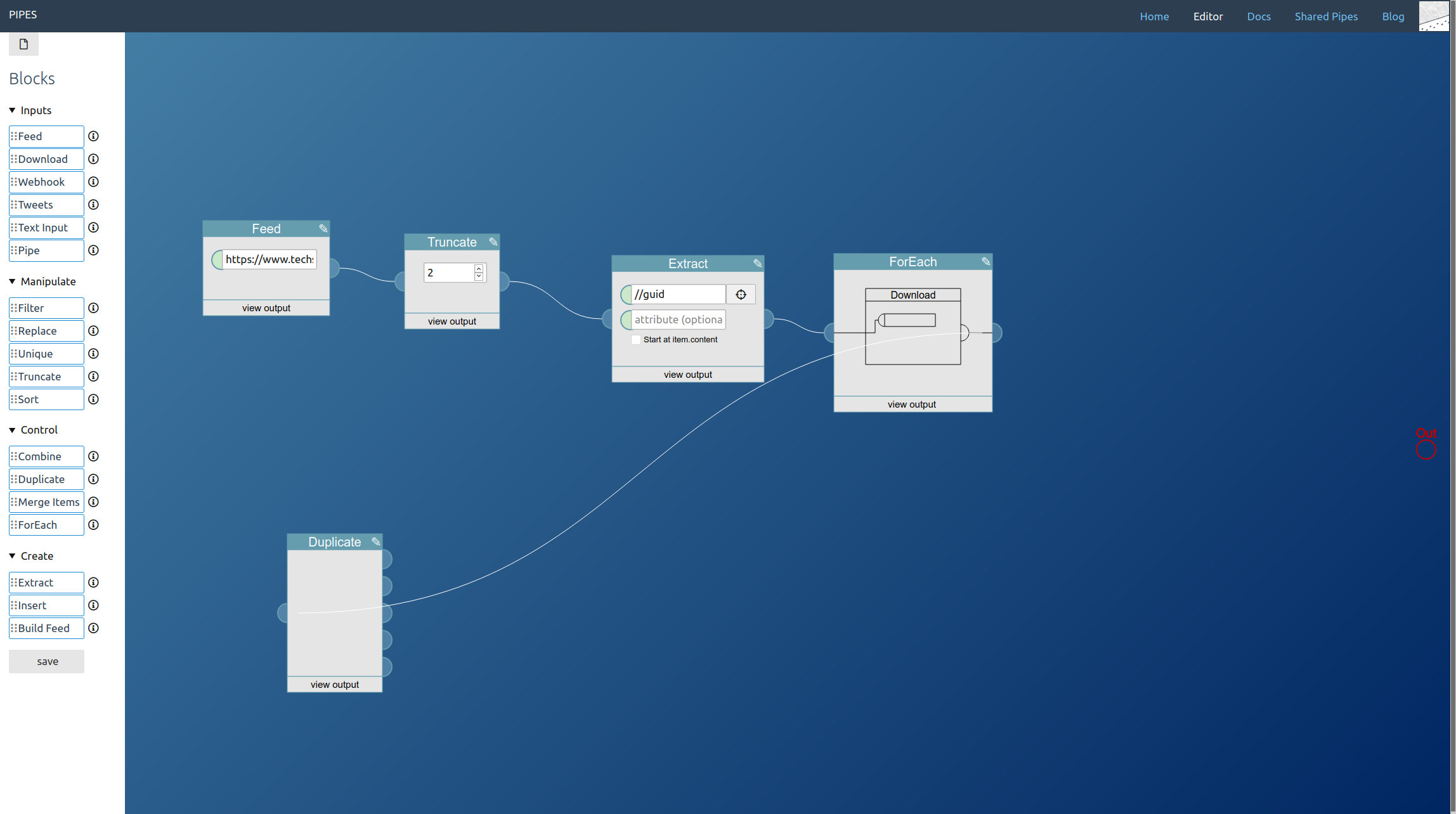
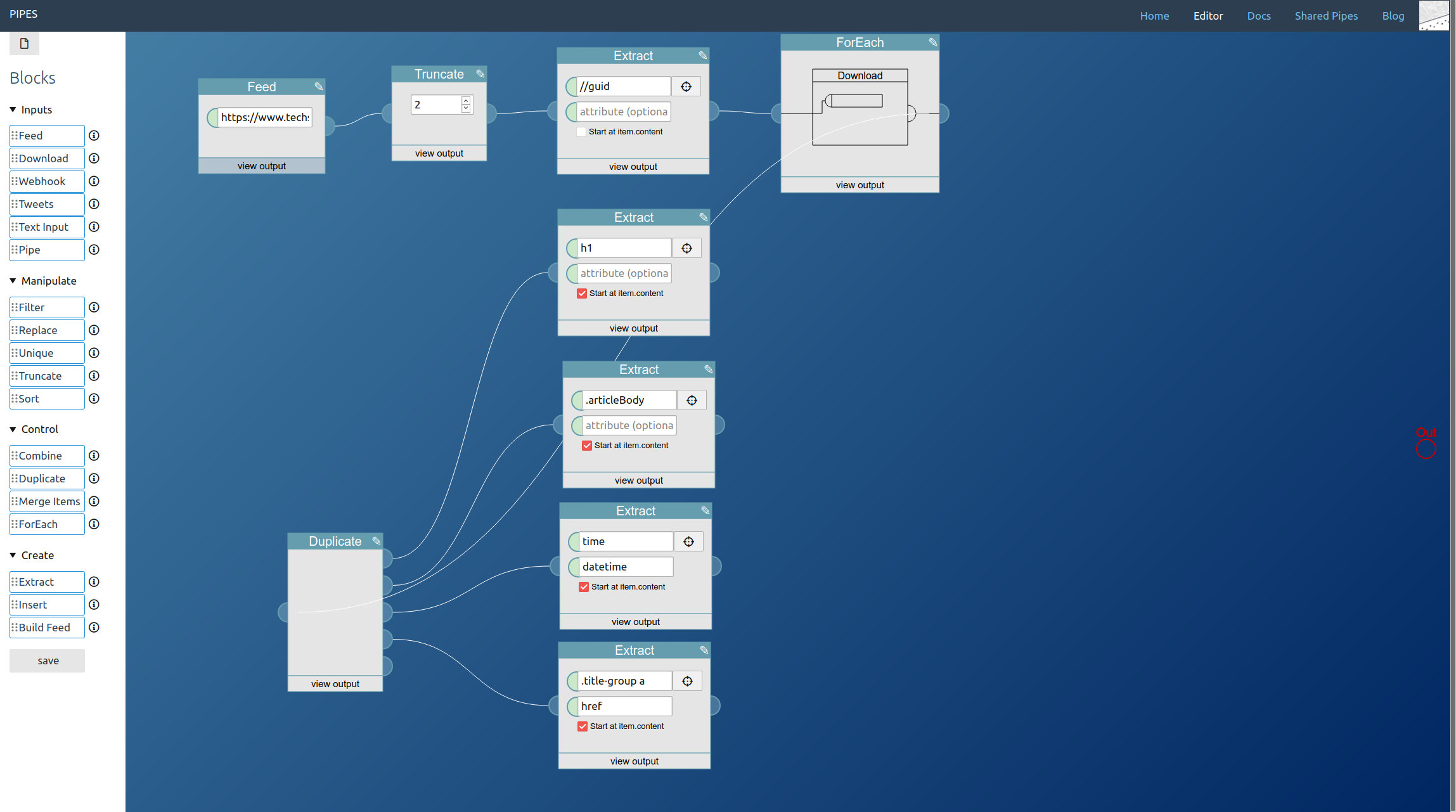
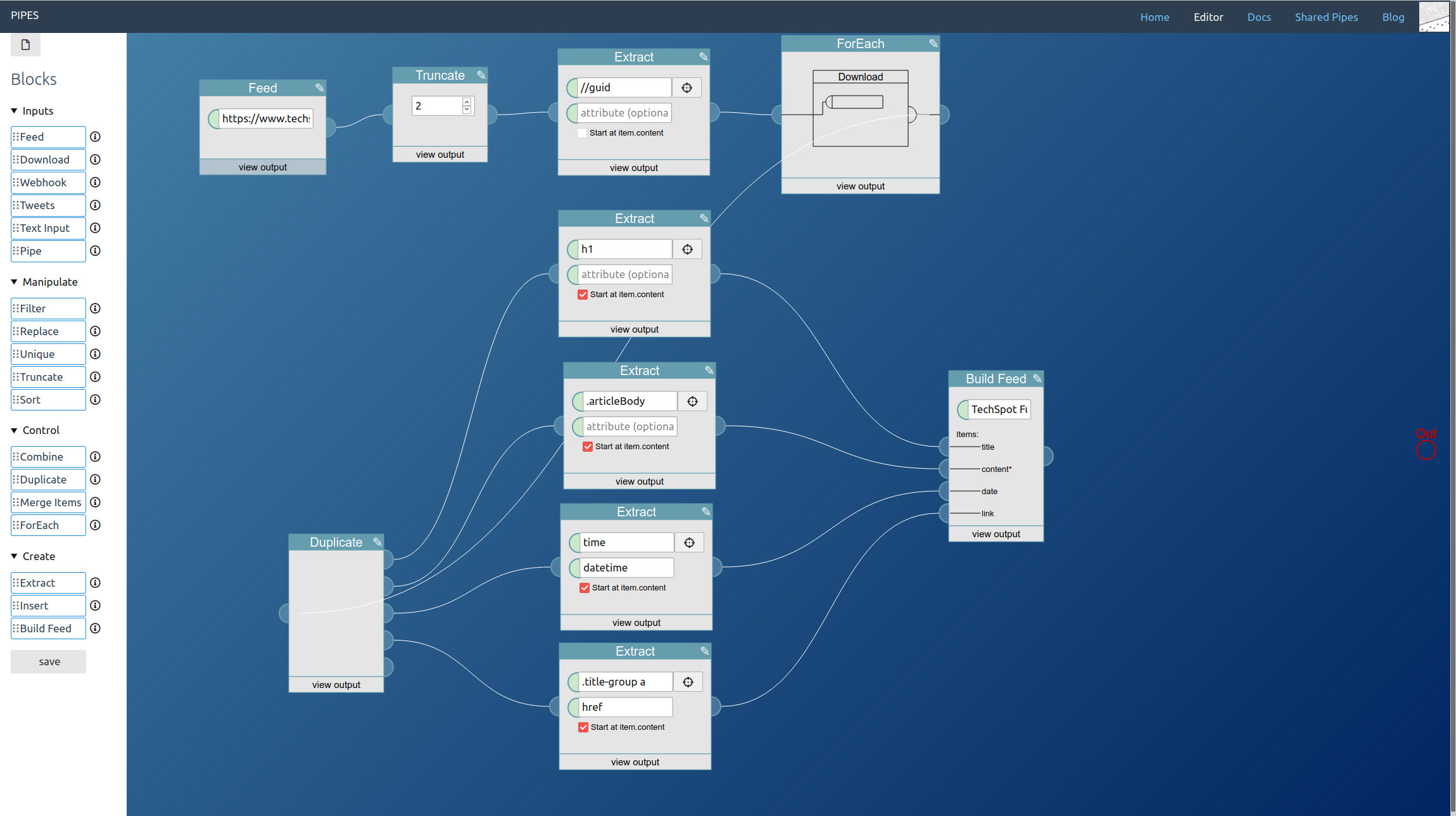
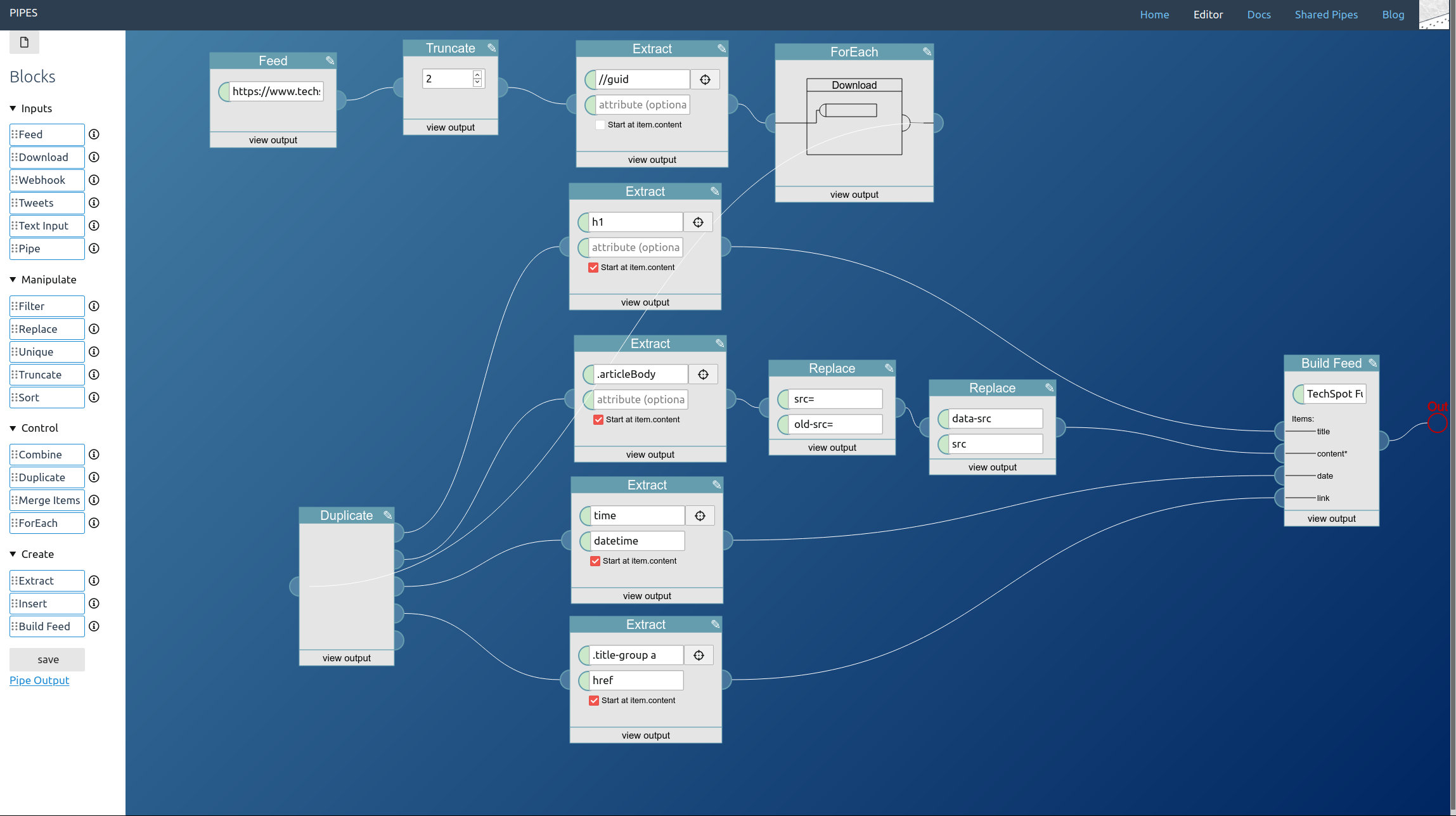
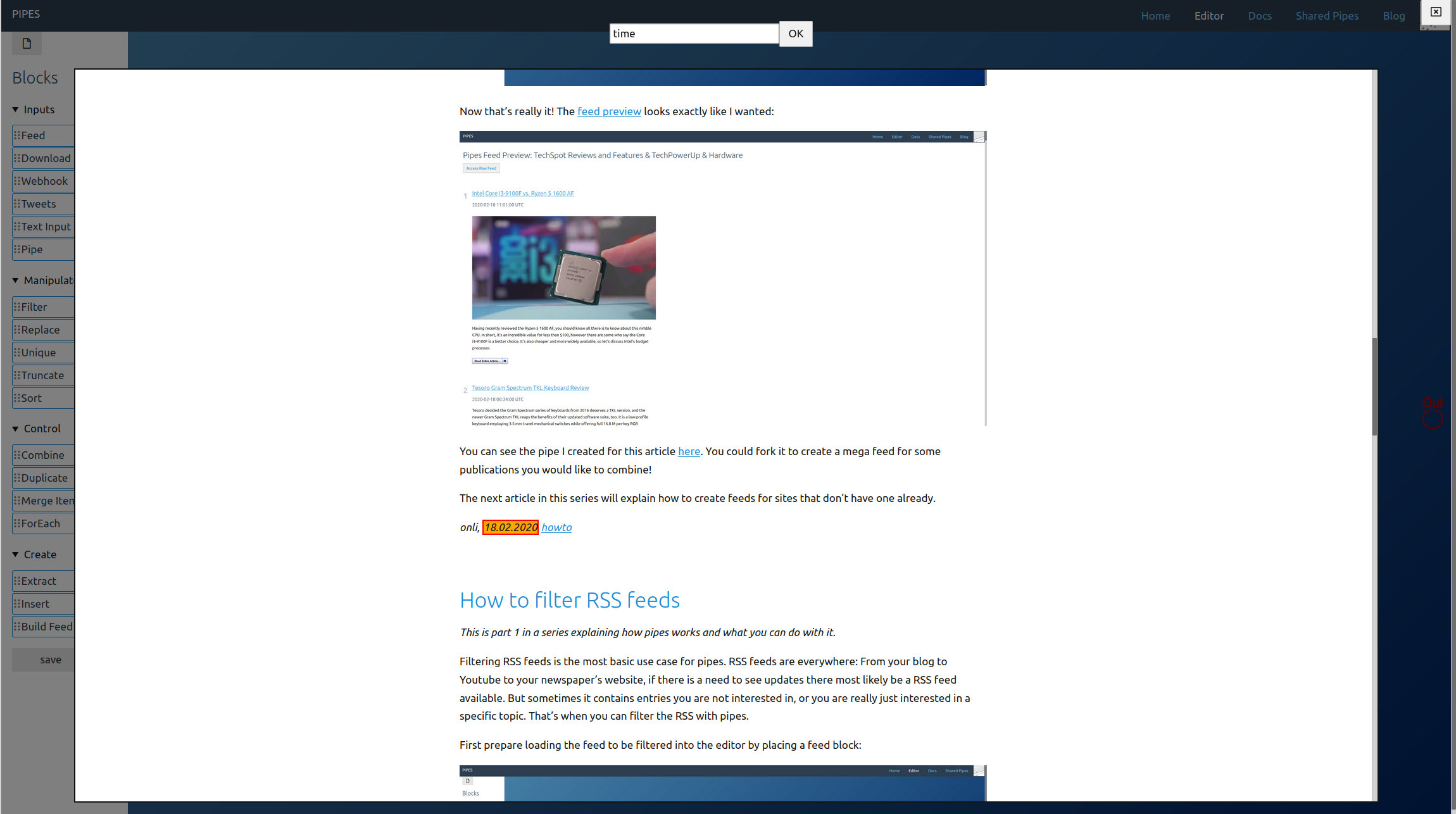
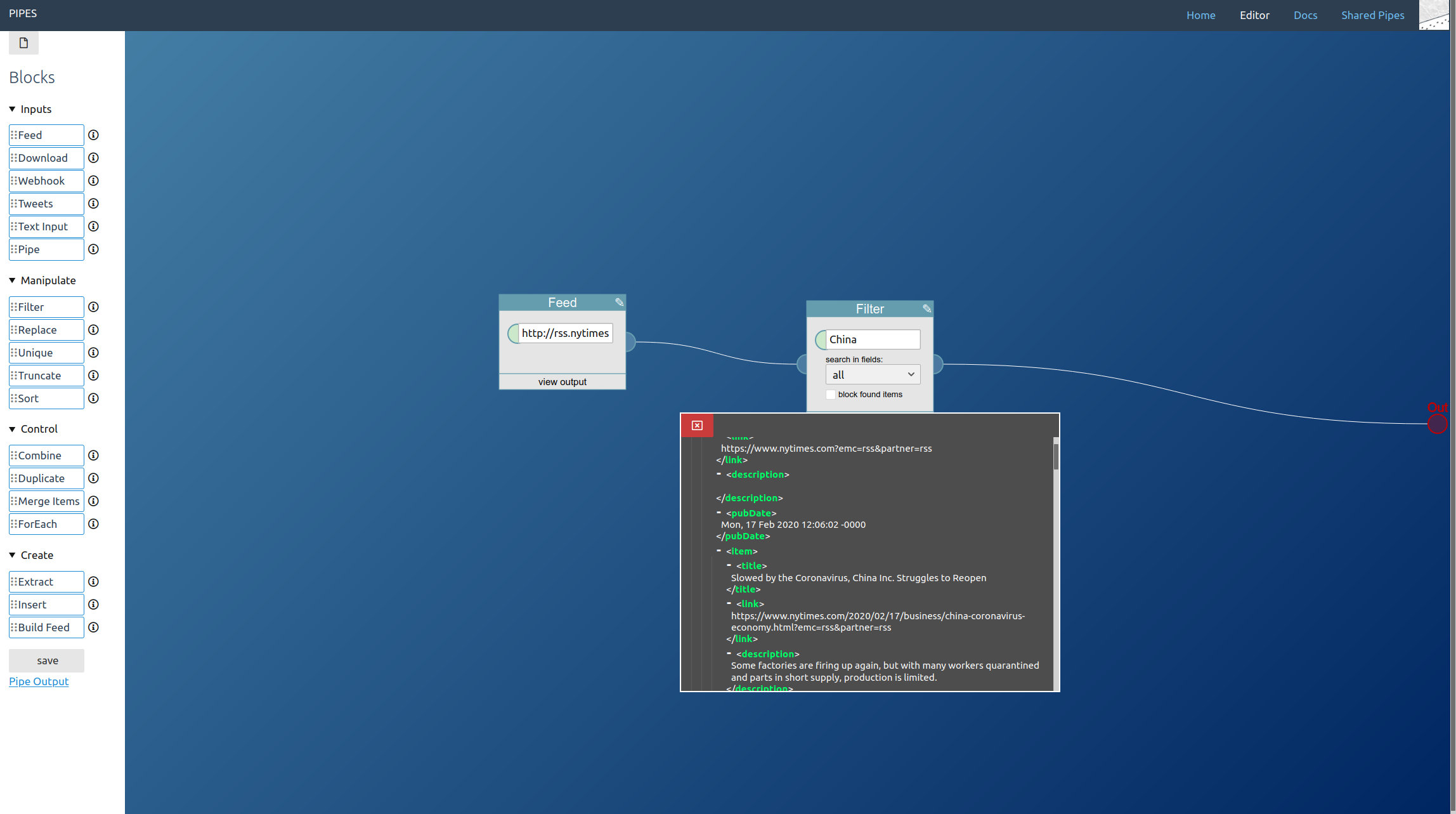
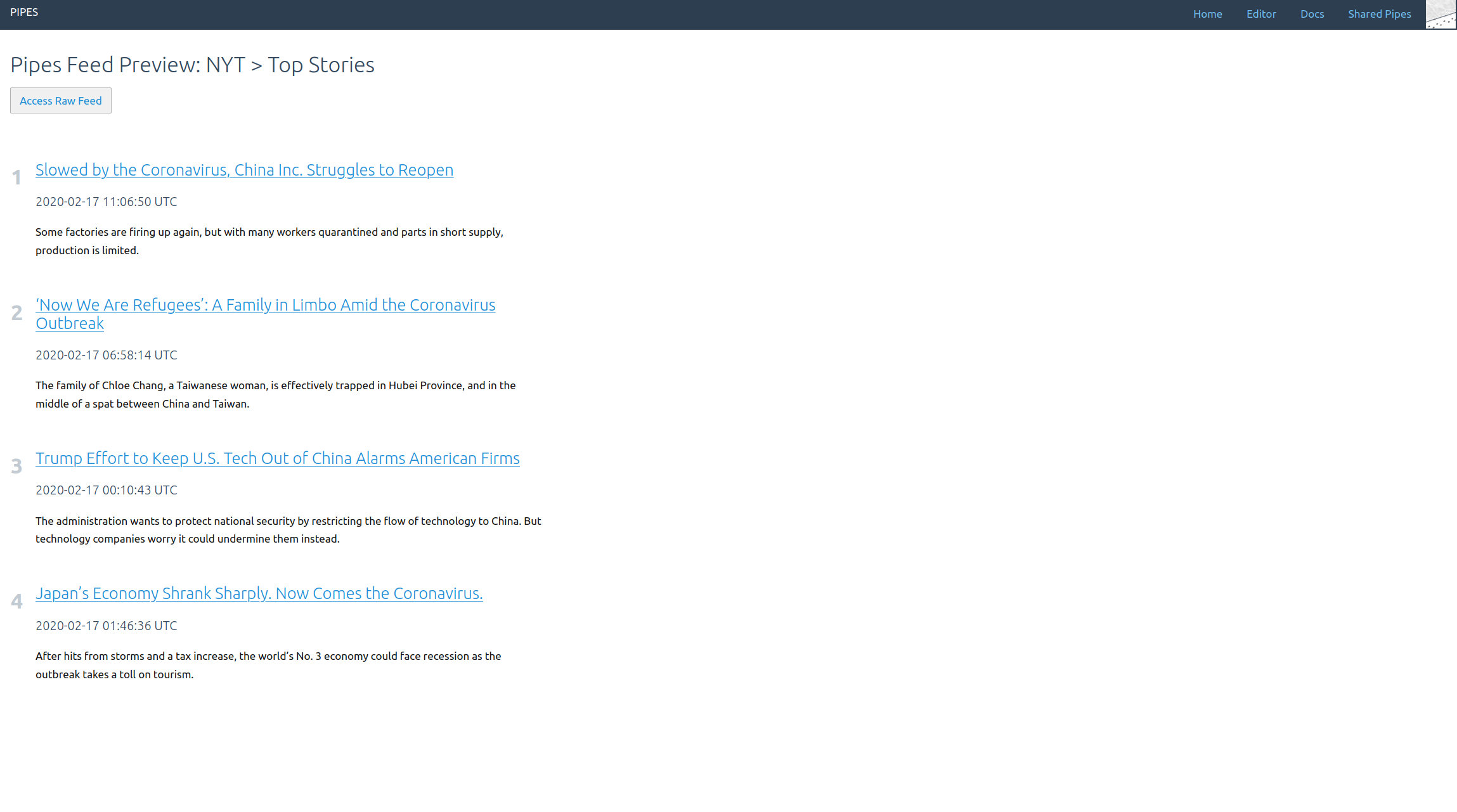
Now in the editor, start by dragging a Tweets block from the left toolbar into the editor area. Pipes supports three modes for accessing tweets. Let’s start with the search, just enter a keyword. Note how in the inspector first tweets appear:
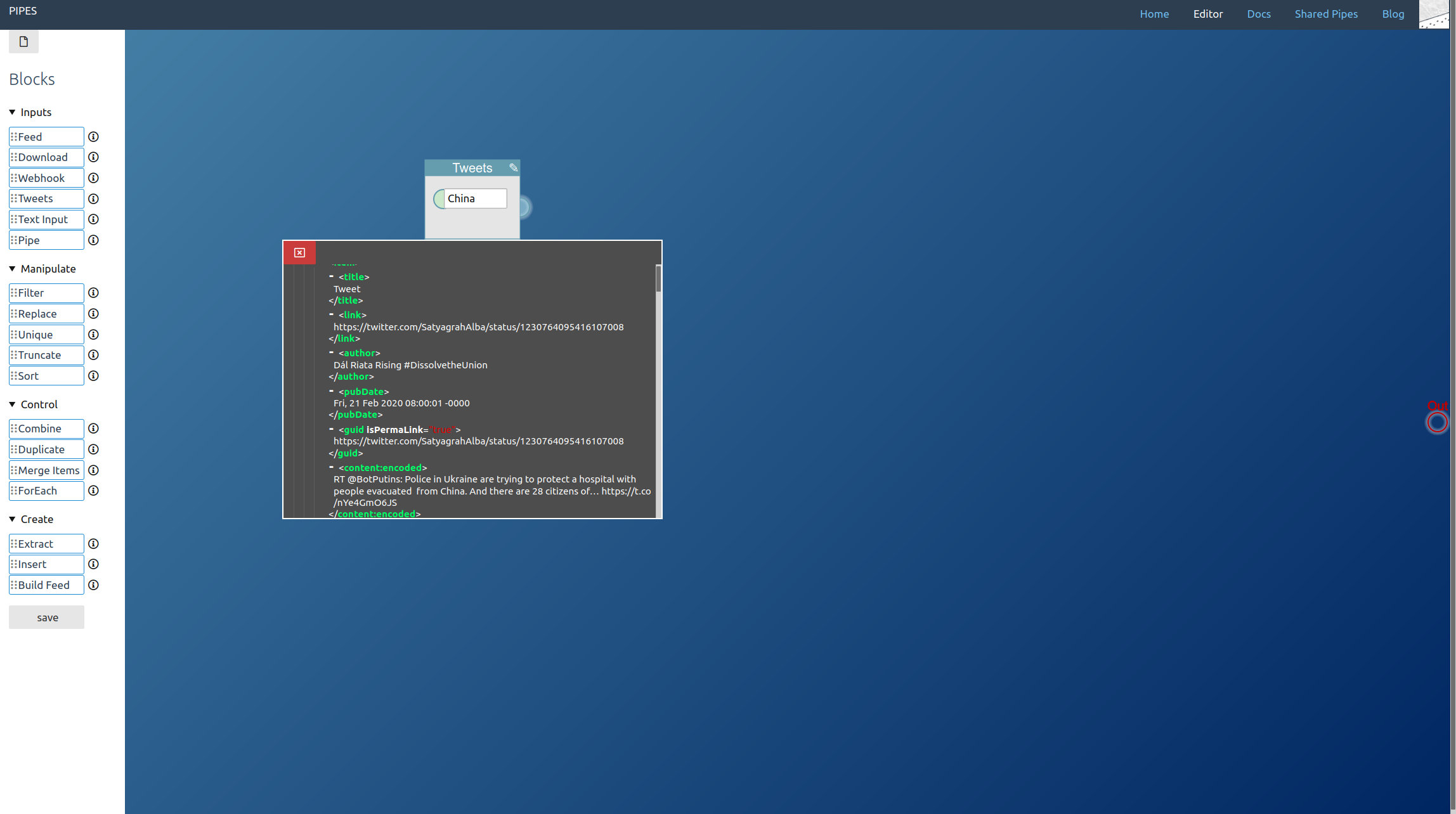
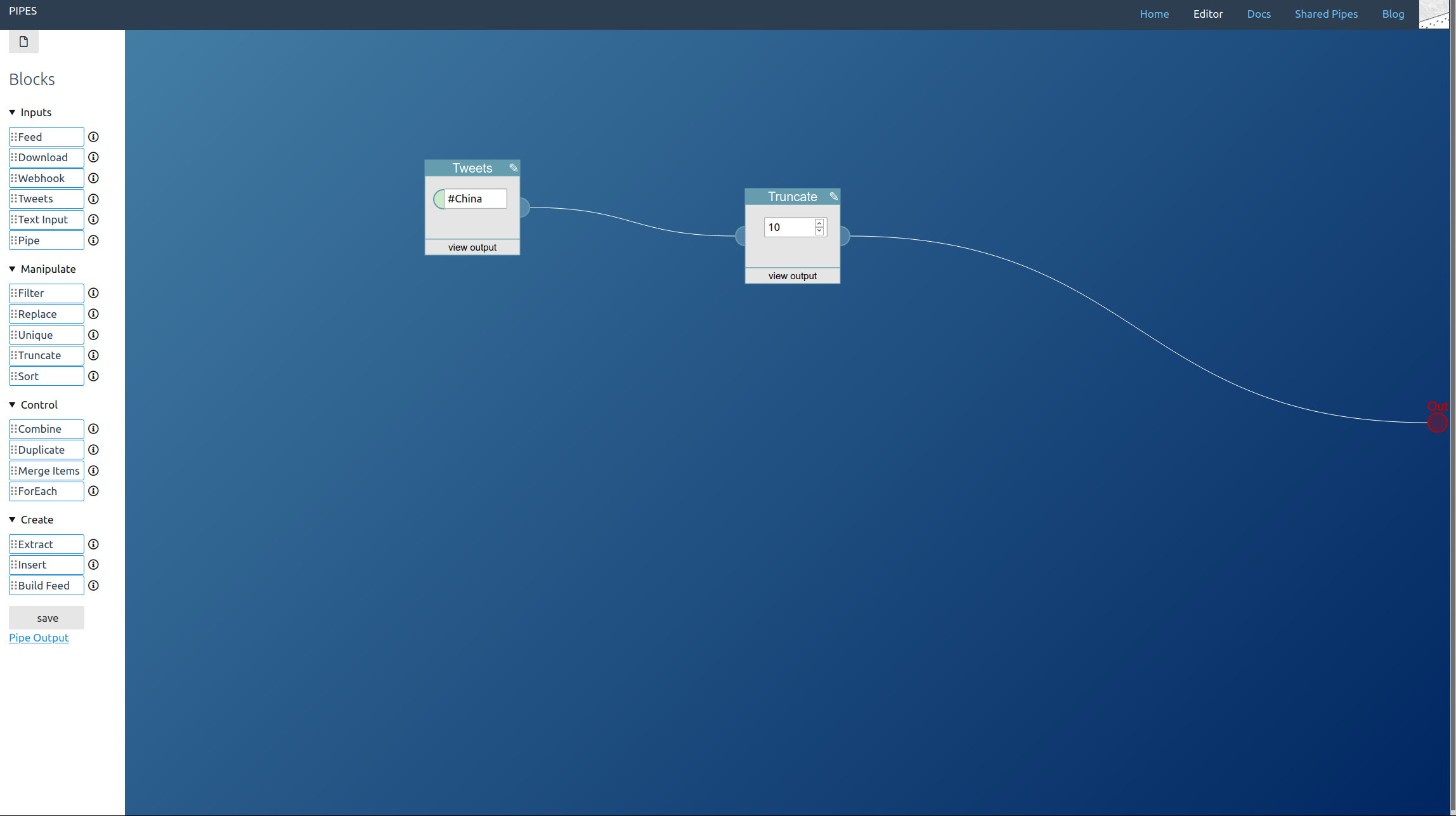
The second method is accessing a hashtag by prepending #. I also added a truncate block, that way we can limit how big the final feed will be:
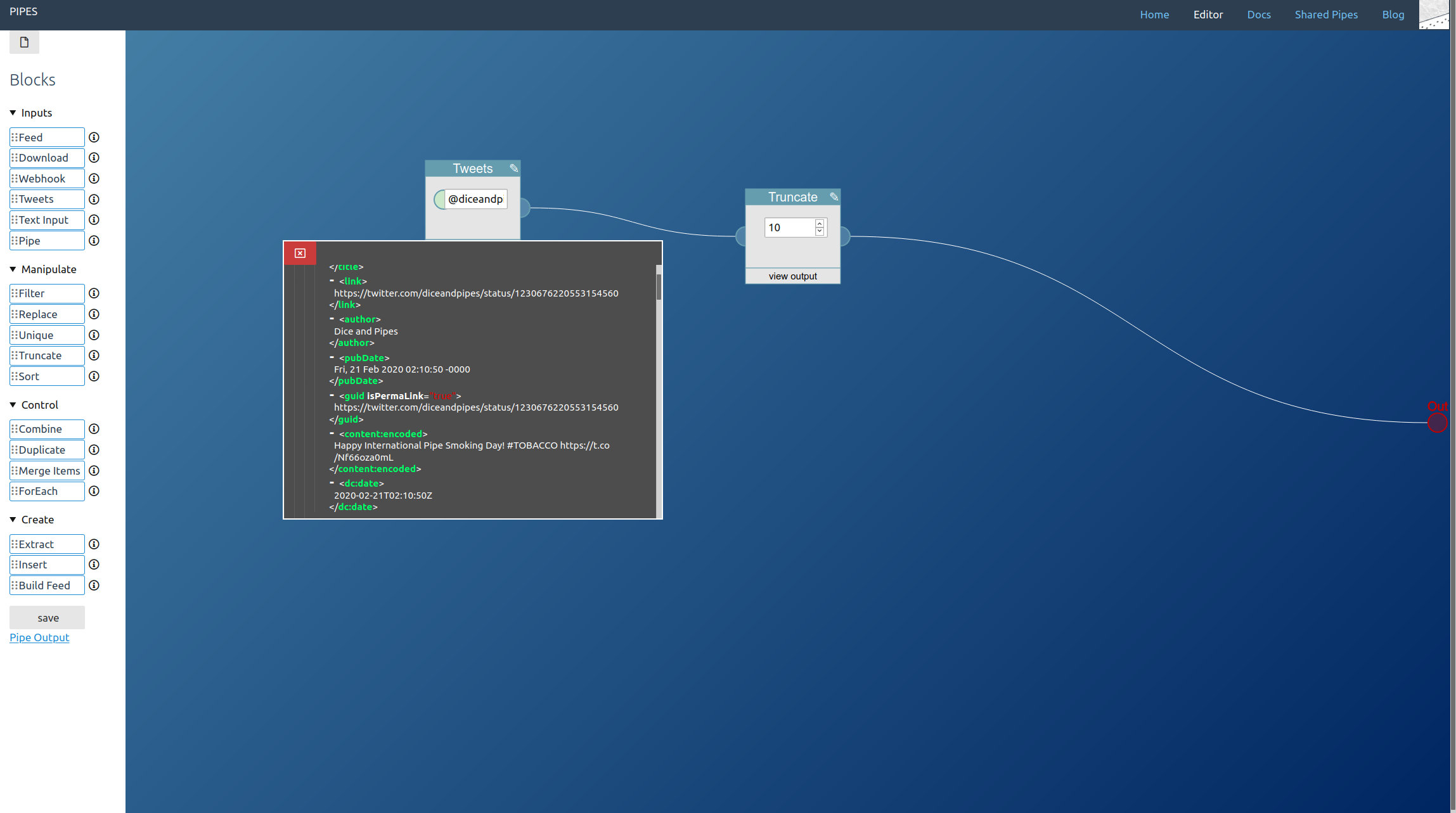
And the third option is accessing the public tweets of a user account, by entering @username:
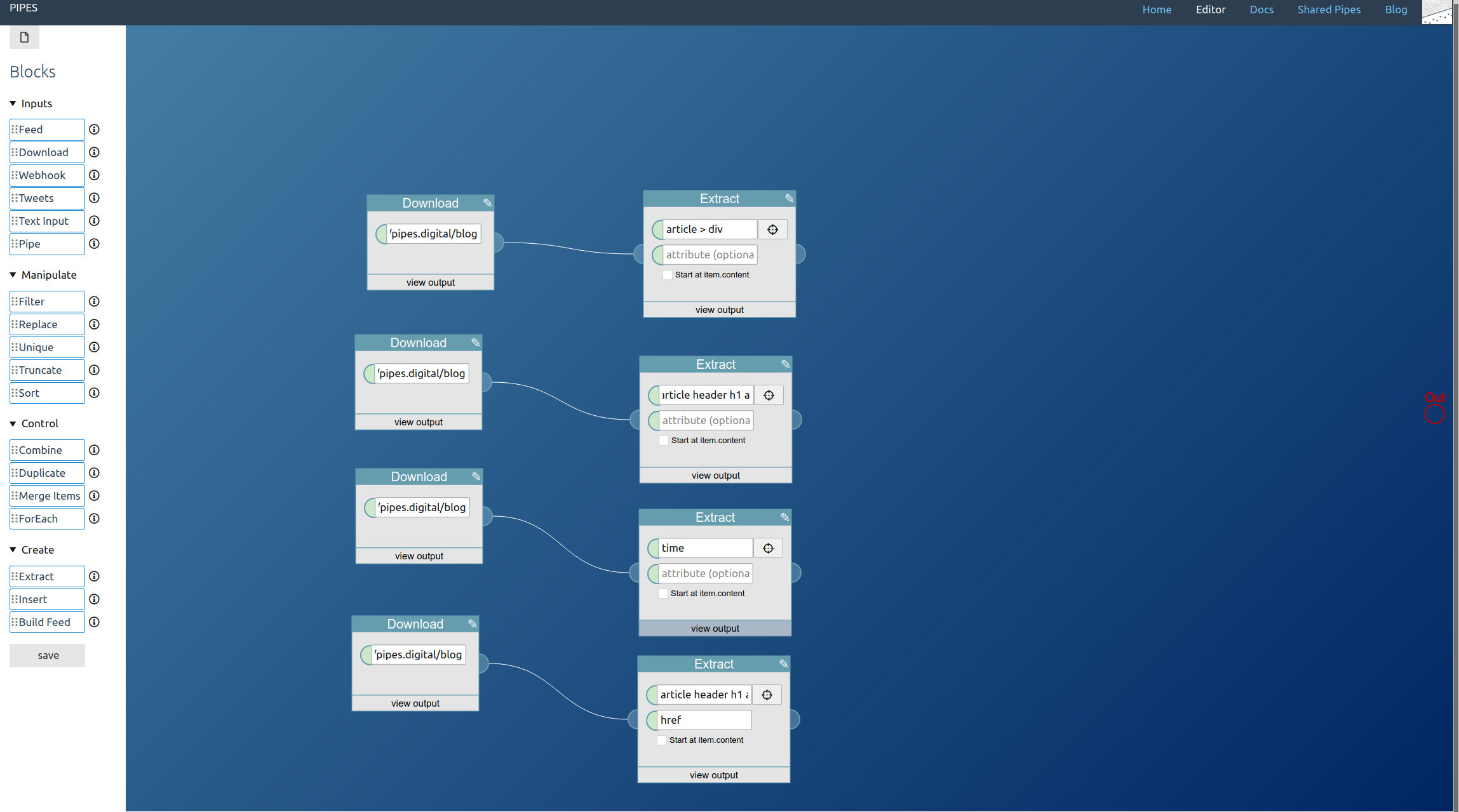
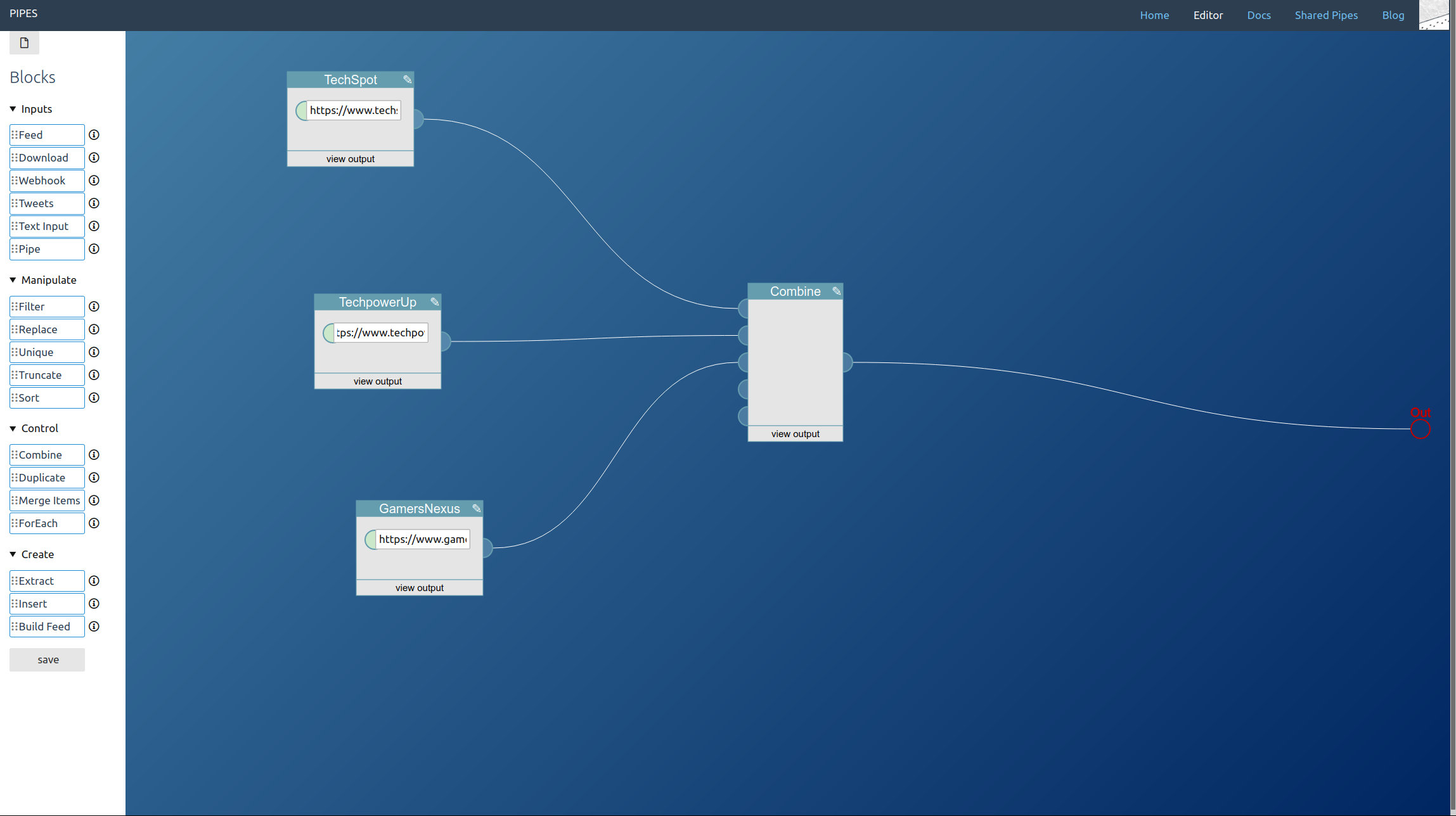
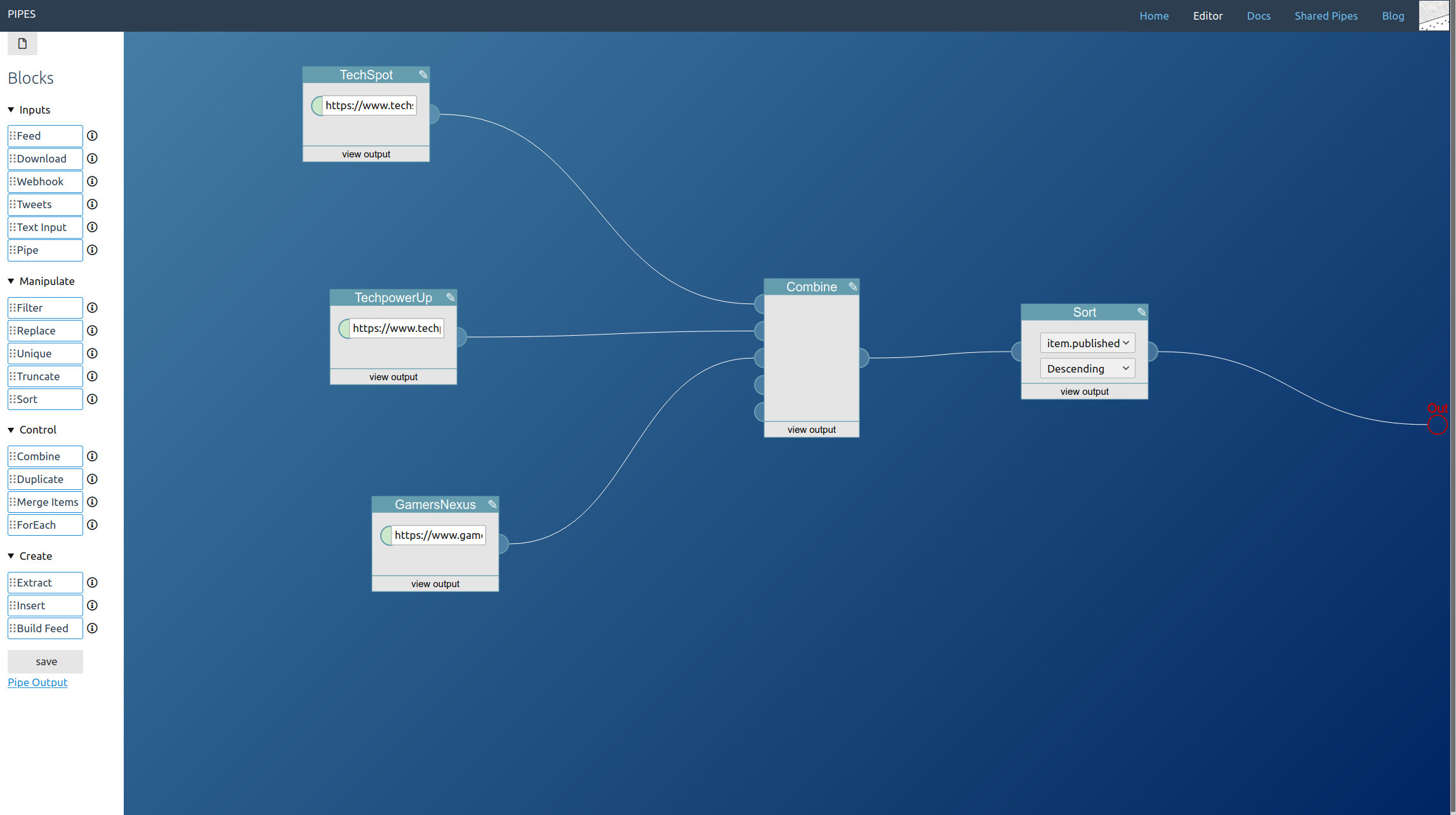
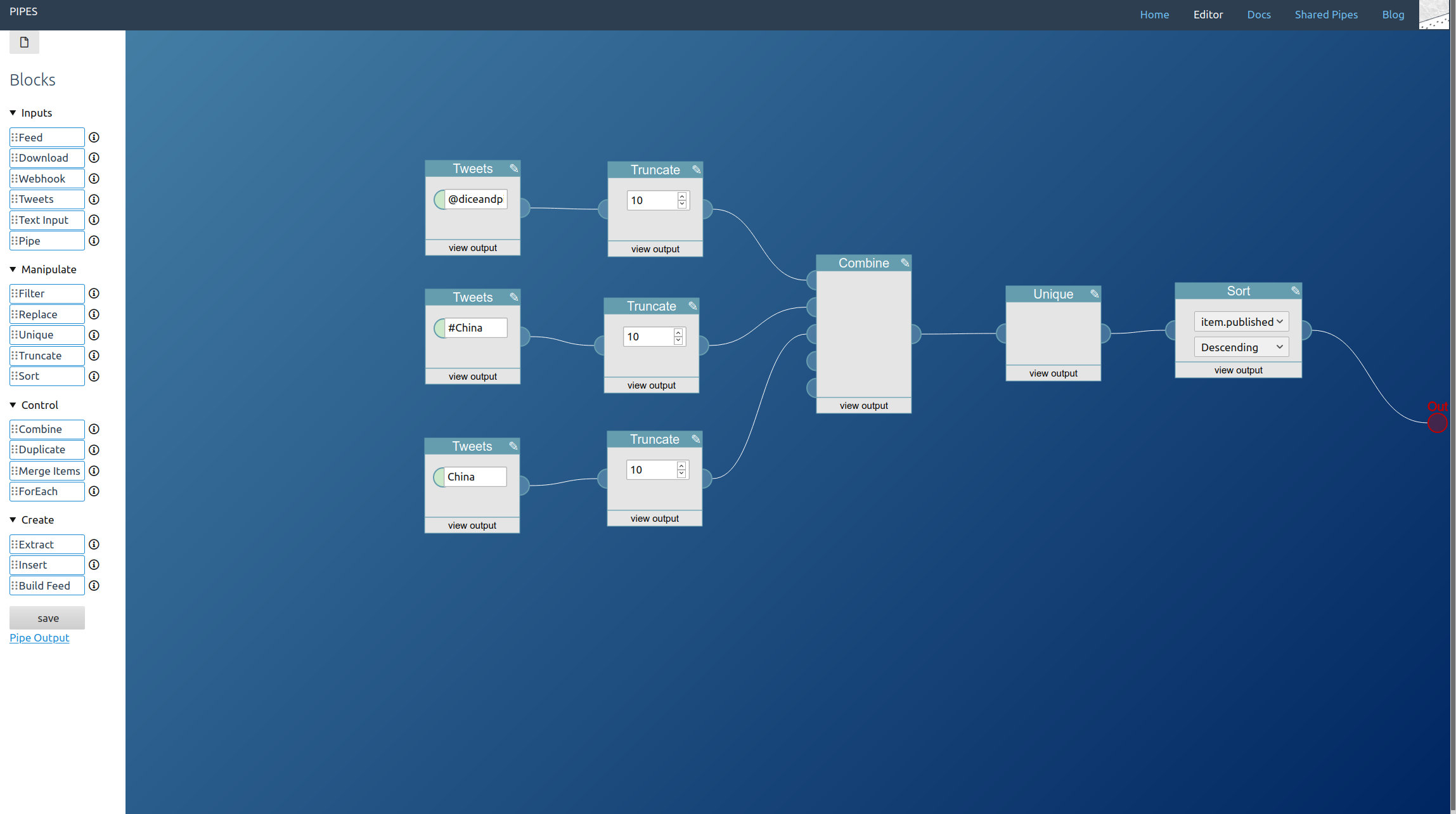
You can combine all three. You place one tweets block for every type of tweet you want to access and lead them to a combine block. Remember that the combine block adds the feeds together block by block, so you almost always want to add a sort block behind it:
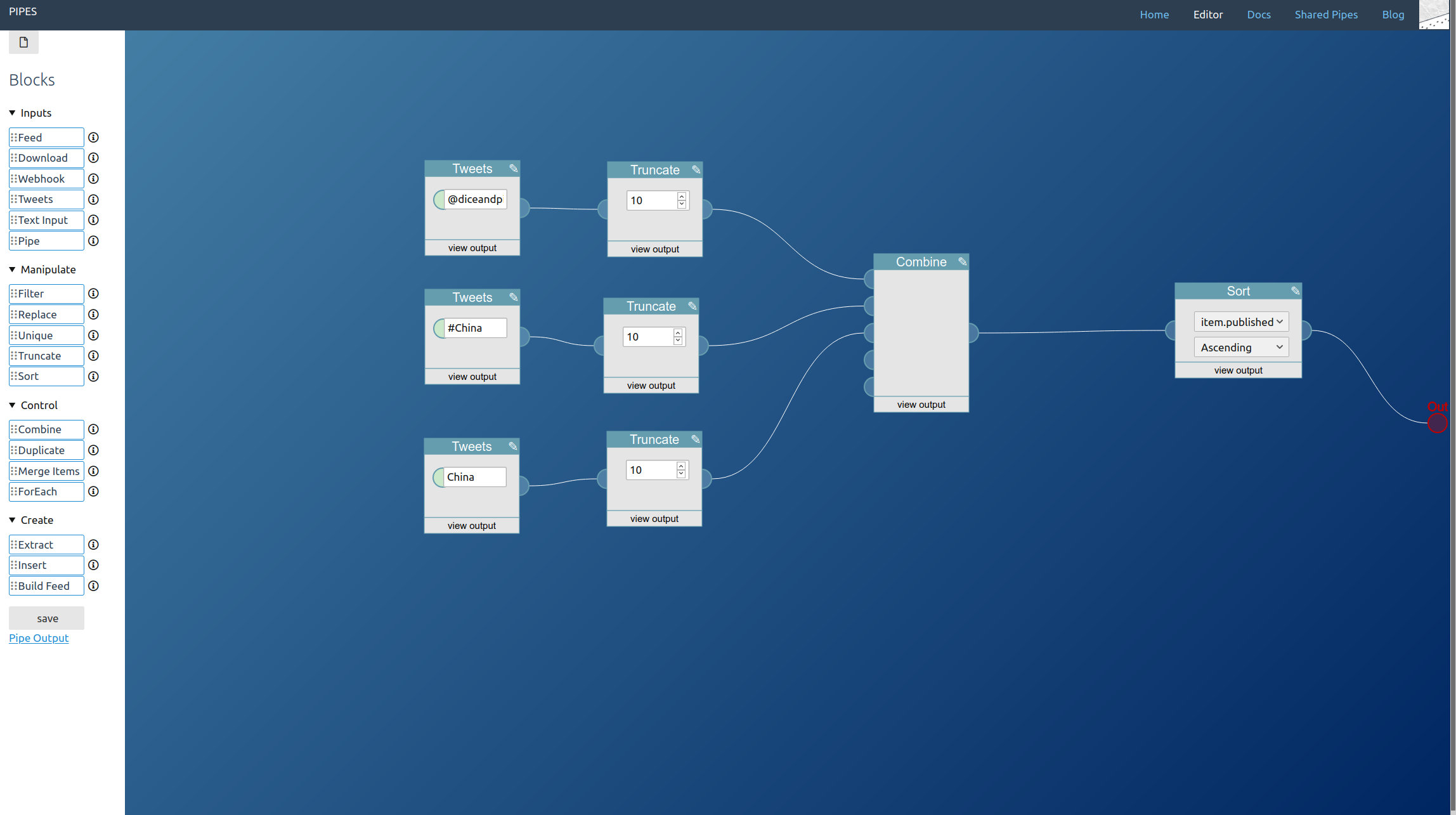
A further small improvement is possible: If like in our example the tweet blocks might output the same tweets, those duplicates can be filtered out by adding a unique block to the mix. Here I also changed the sort order to the more twitter like descending:
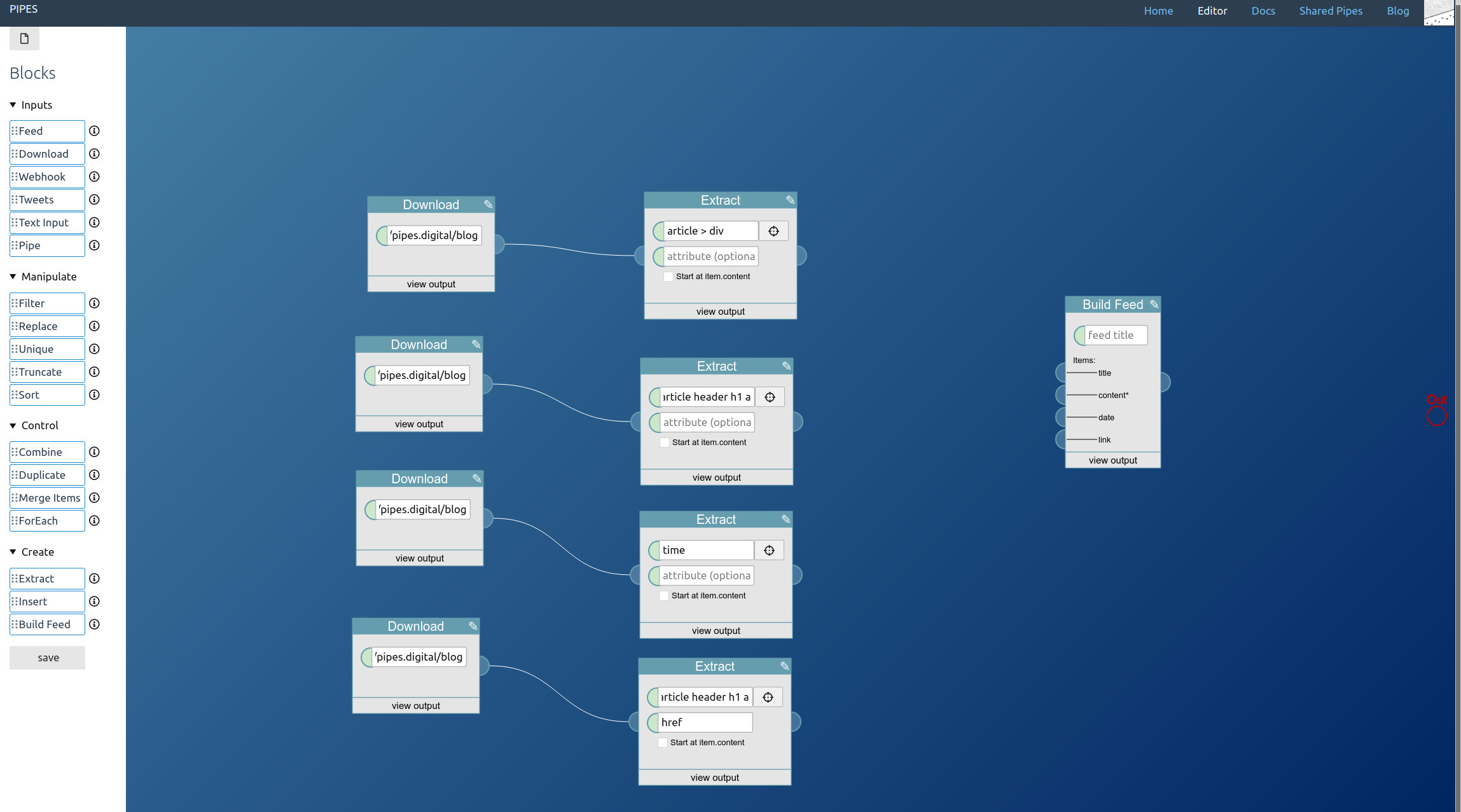
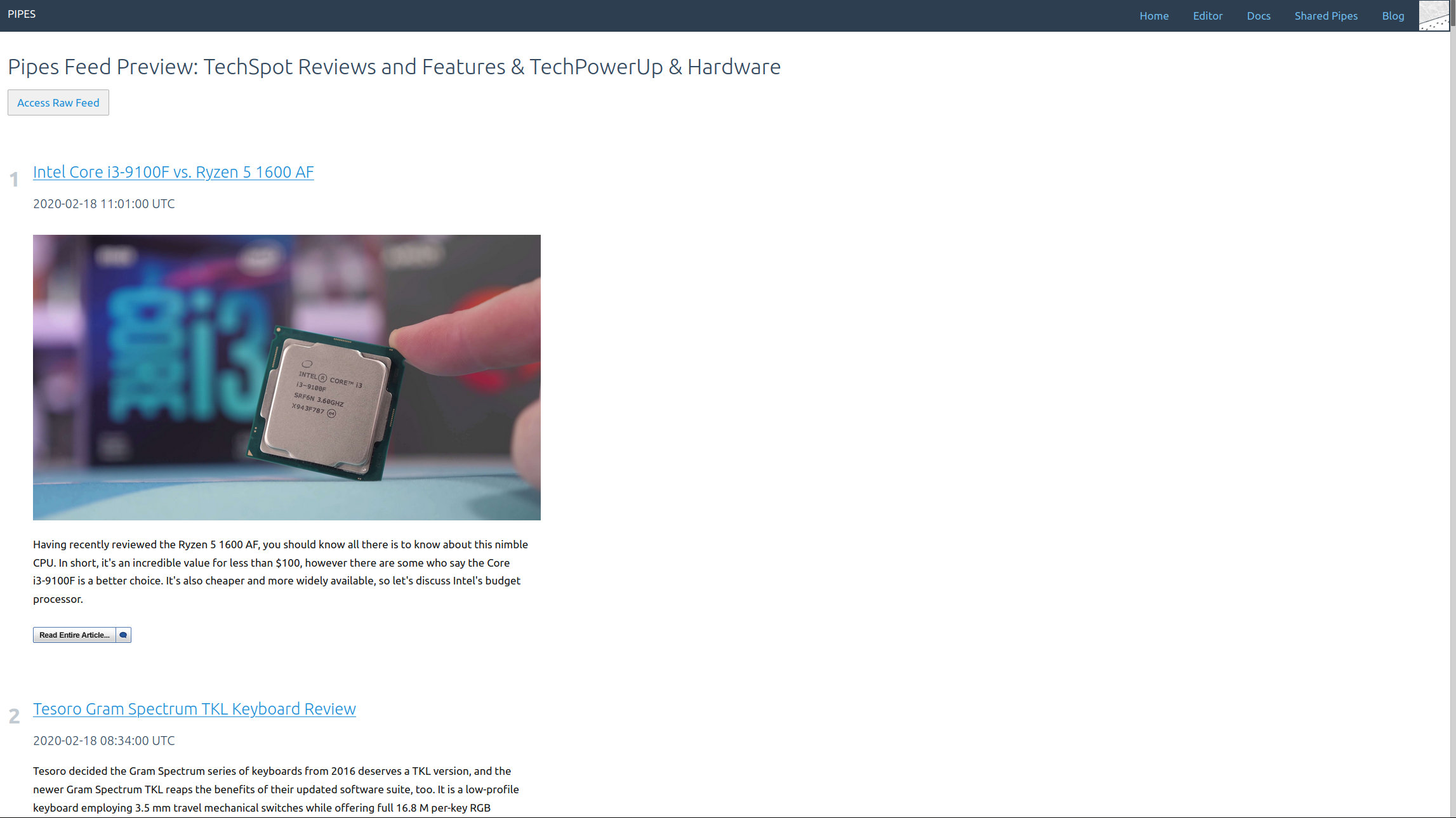
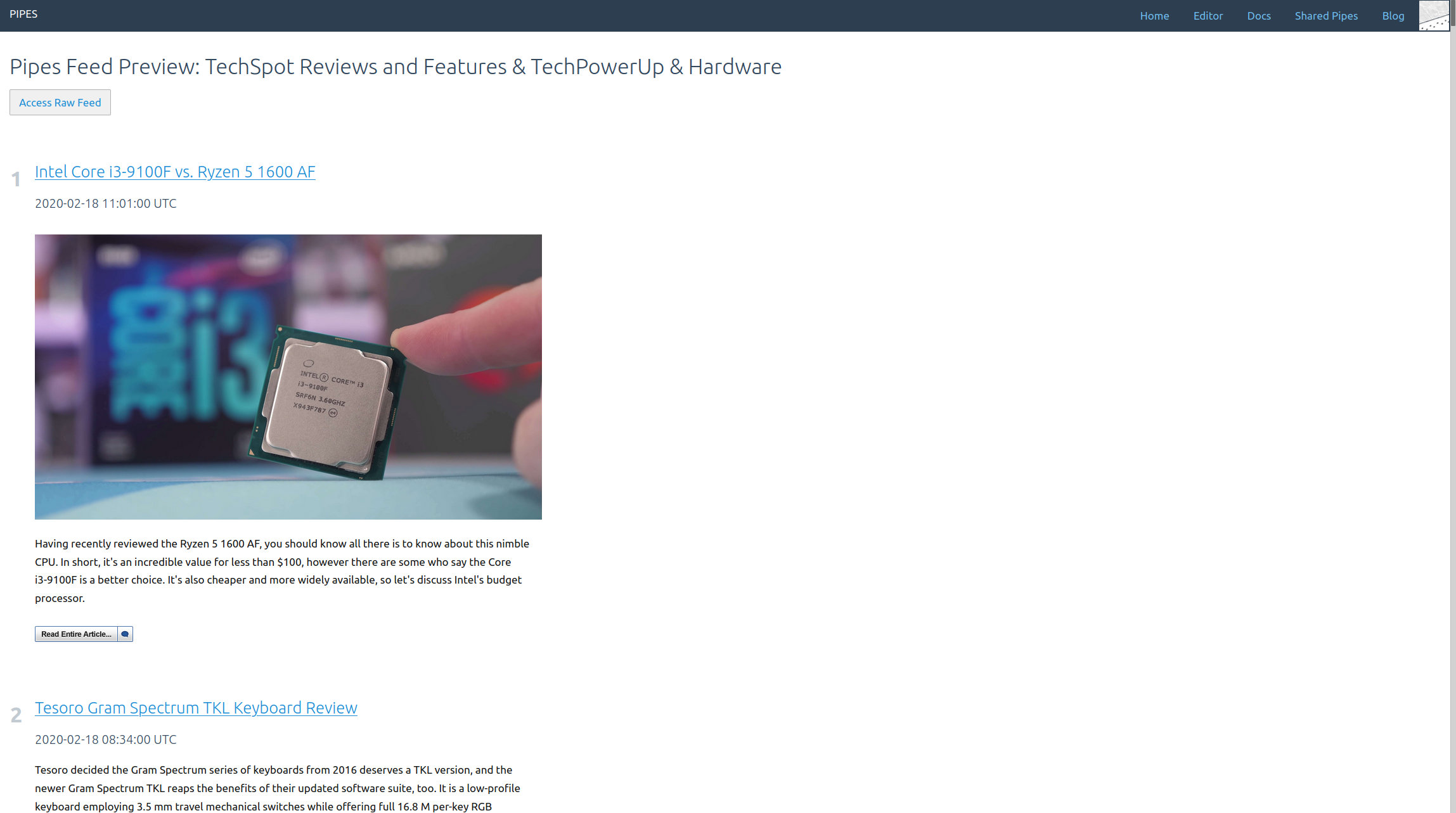
And that’s it. Adding tweets to your pipe is as simple as adding a tweets block. The result is a working RSS feed (with a rather strange mix of tweets in this example) you could use anywhere you want:
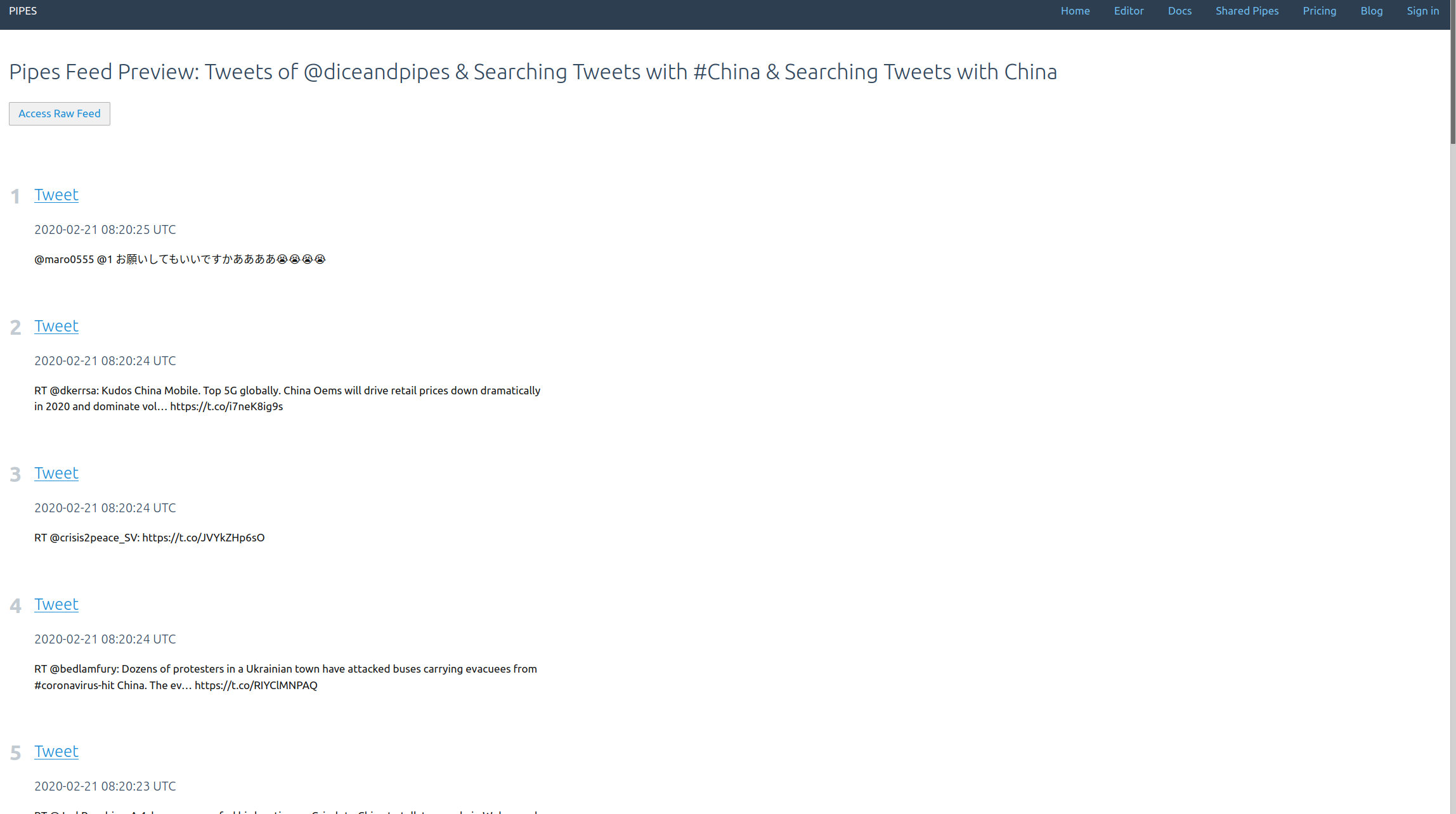
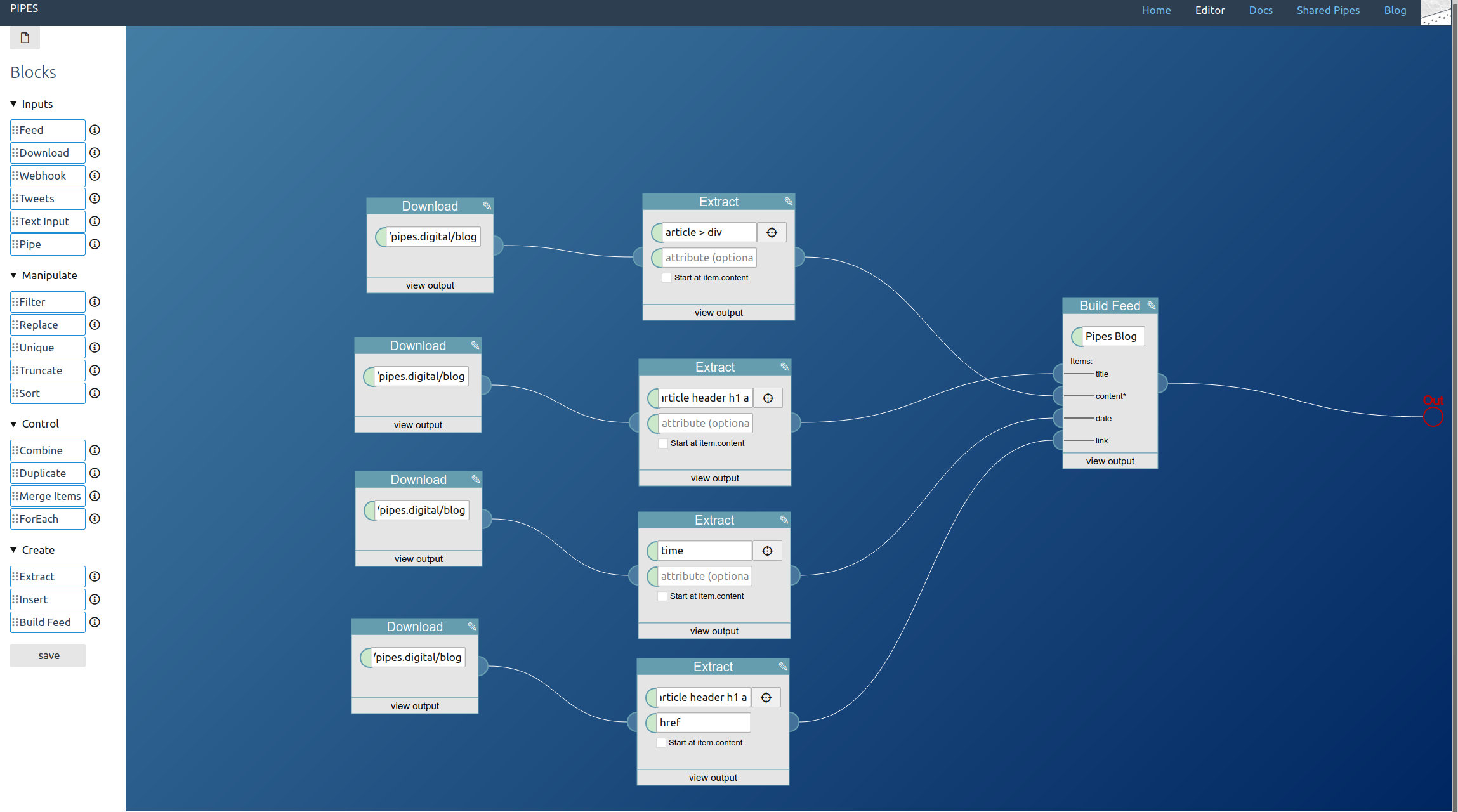
You can see the pipe I created for this article here. You could fork it to access the tweets for hashtags, accounts and search keywords you would prefer.