This is part 3 in a series explaining how pipes works and what you can do with it. Read part 1 to learn how to filter feeds and part 2 to see how to combine feeds.
Now that we saw how to filter and combine feeds, what to do about sites that don’t provide an RSS feed? Is there no way to work with them in Pipes? There is, if it’s a HTML site. Pipes can download the site and extract the elements needed to create a proper RSS feed.
Let’s start by creating a new pipe.
First, drag a download block from the toolbar in the left in the editor area:
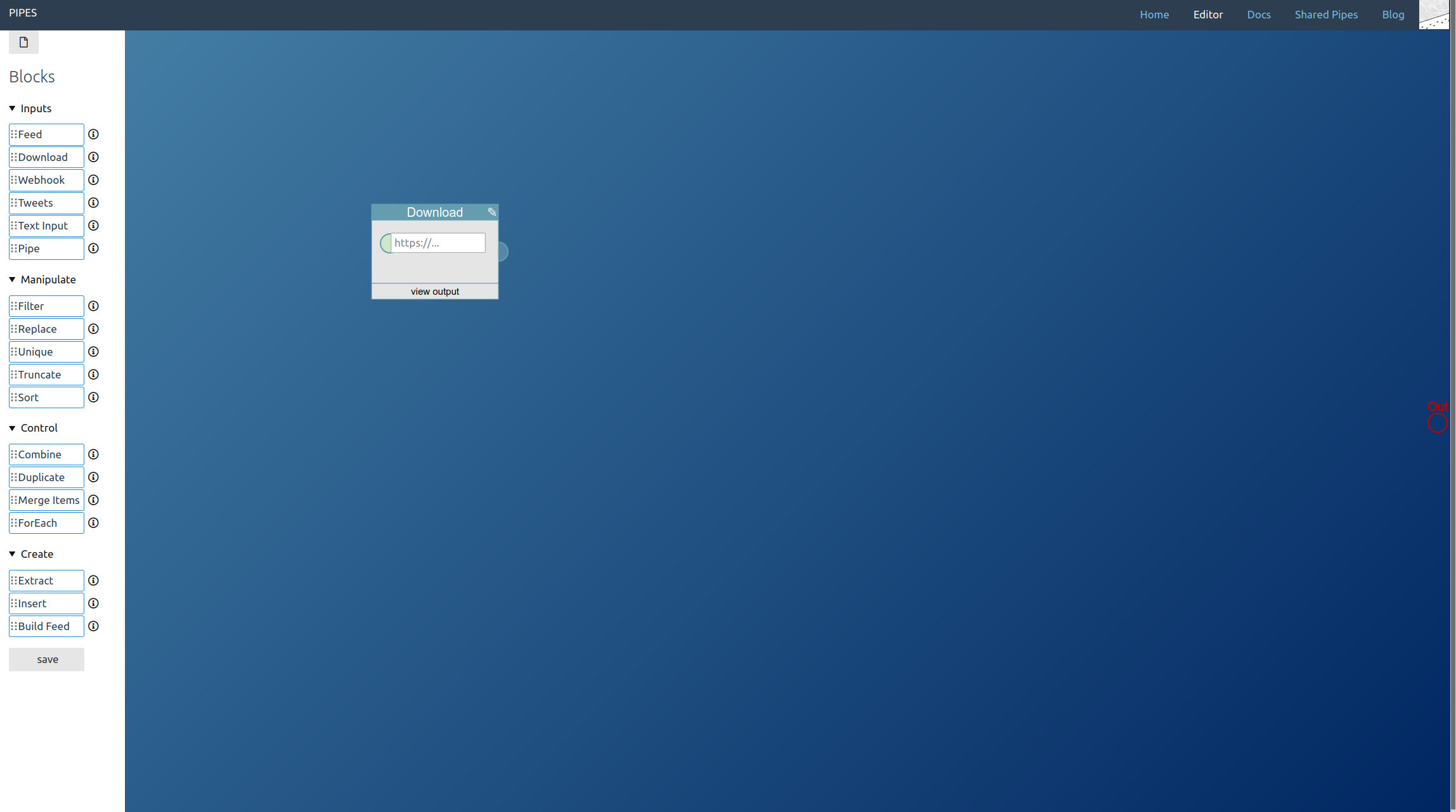
The example here will be this blog, so enter its url https://www.pipes.digital/blog/. Now add an extractor bock, and connect it to the download block:
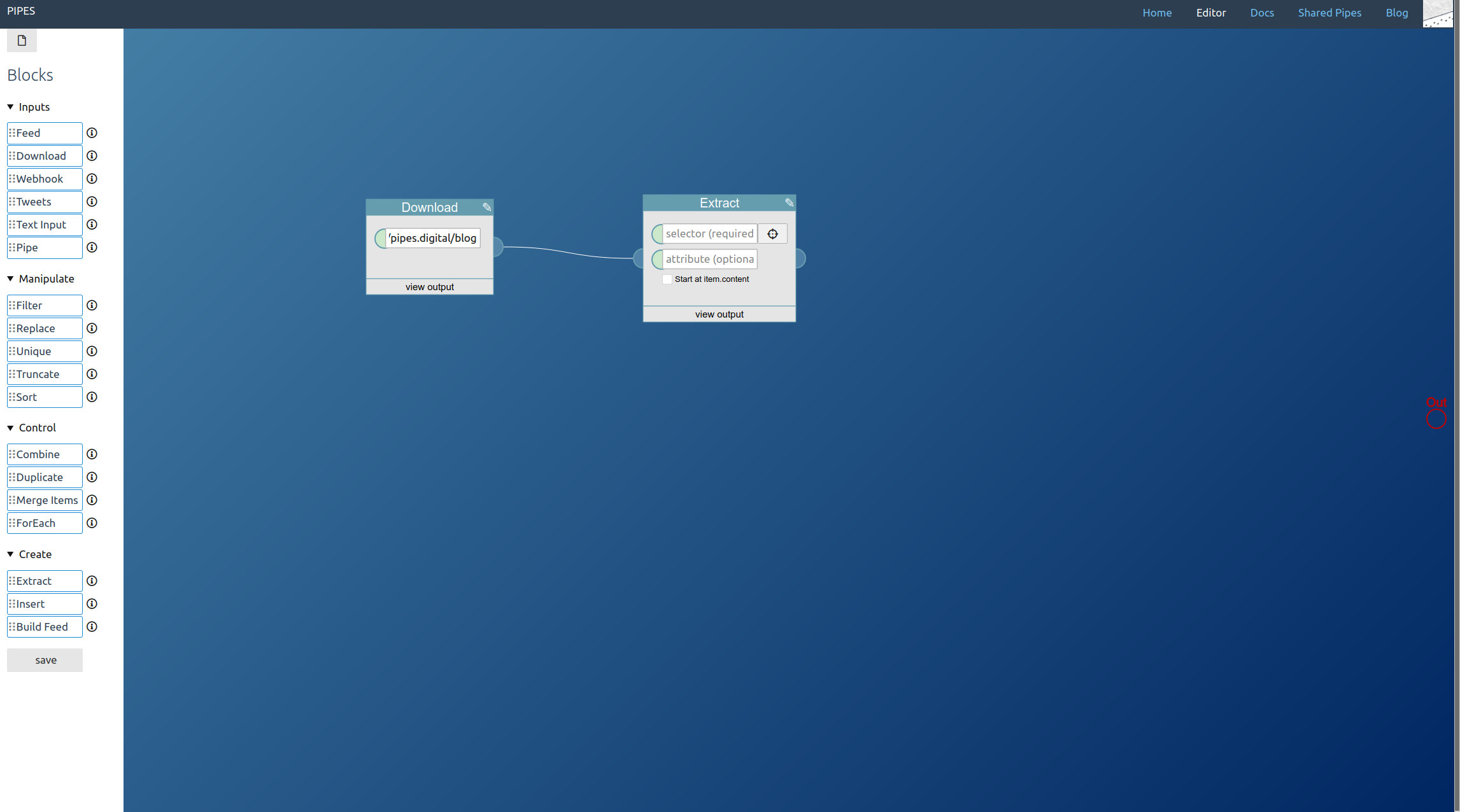
You see that it asks for a selector, and CSS selectors work best for HTML pages. The correct selectors will vary for every site. There is a helper tool, but we can also enter the selector manually and should start with that.
To find the selector, I think it’s easiest to inspect the target site with your browser to find those (In Firefox: Right click on something on a page and click on Inspect Element). Then you can look at the HTML and create a selector based on the structure, ids and classes. For example here in this blog, to get the article text I’d use the selector article > div:
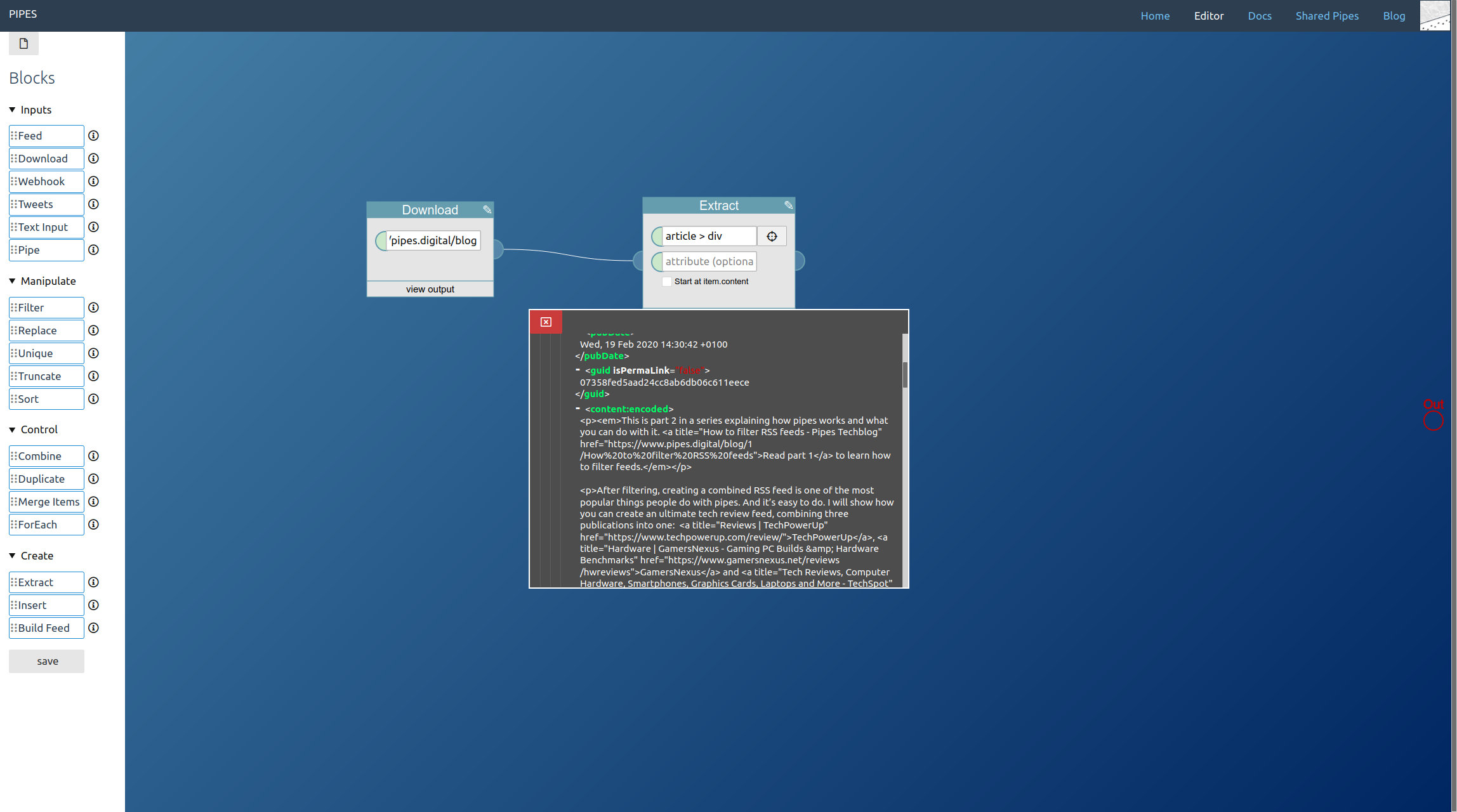
But we need three more things: The article titles, dates and links.
For the date we can try the selector that comes with the extractor button right next to the selector. An overlay opens:
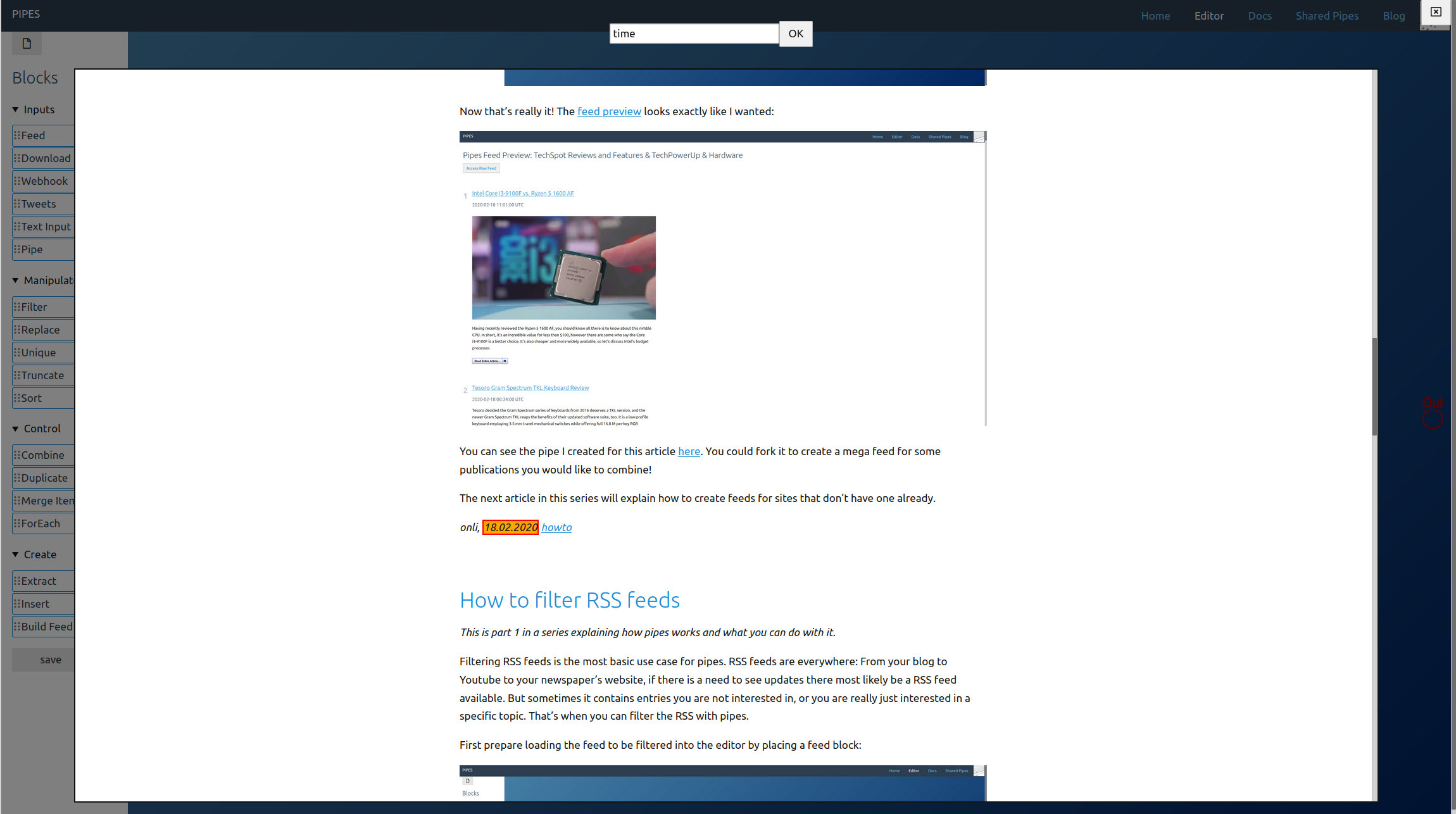
In this overlay, if you click on an element it tries to find a selector for it. If you click on a second element, the tool will try to extend the selector to also match it. If you click twice on an element that marks it as a non-target. In this example a simple click on the date is enough to get the correct selector, time. Click on OK at the top to use the found selector and close the overlay.
Article title and link both come from the title of the entries here, and that’s the same selector article header h1 a. For the link, the difference is that we grab the content of the href attribute:
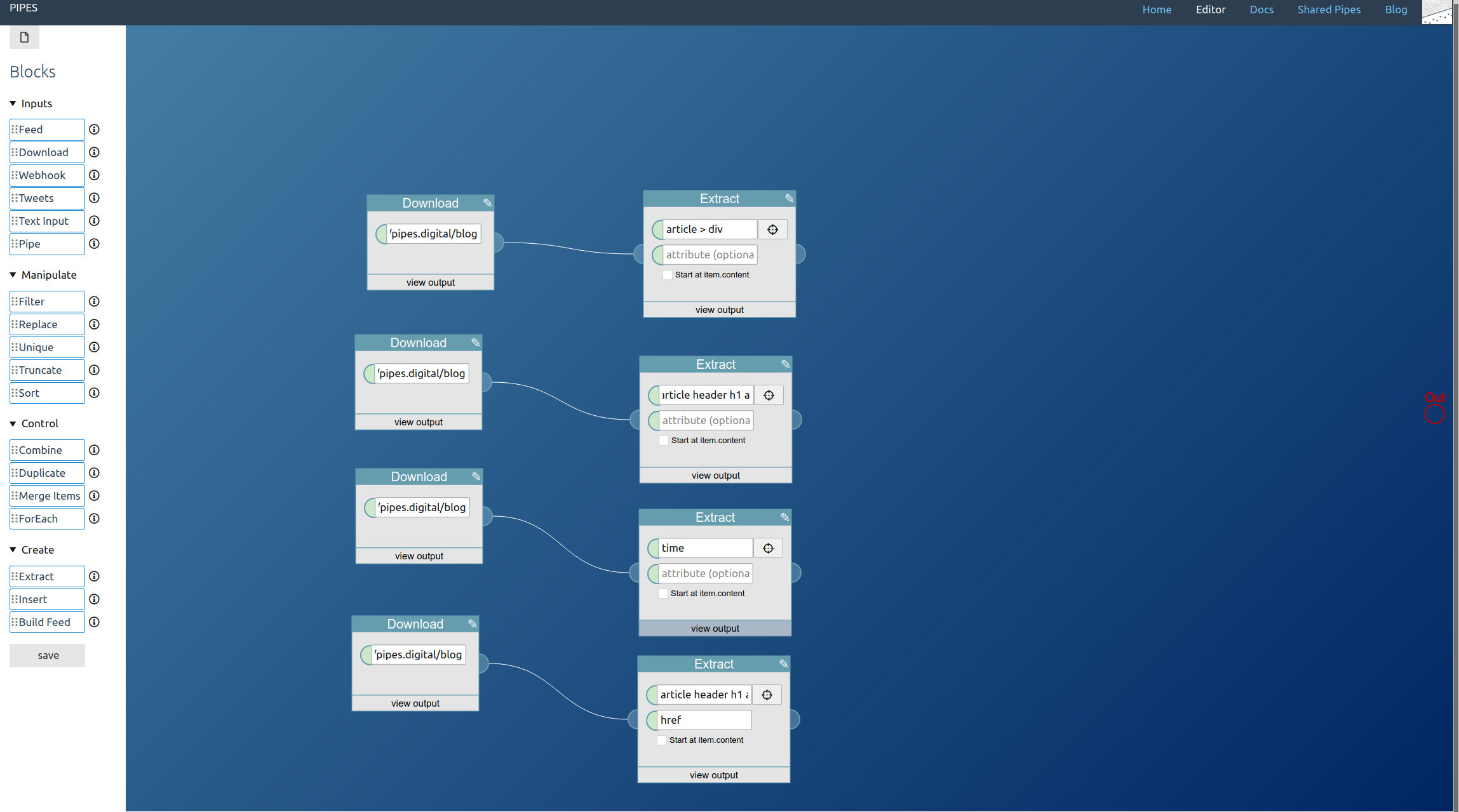
Now we have everything we need to construct the feed. Place a Build Feed block:
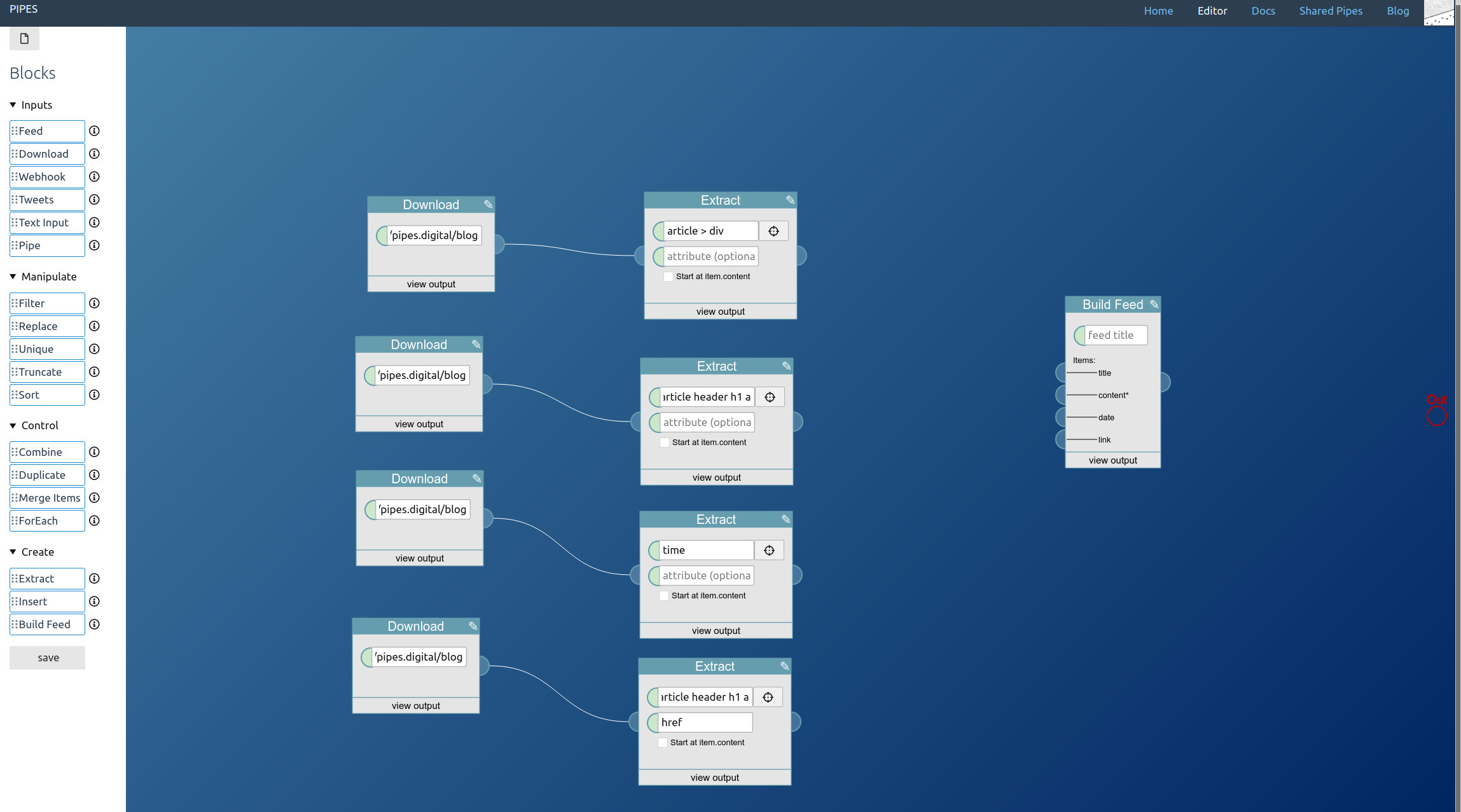
It gets a title (for the whole feed) and takes 4 inputs, for the items content, title, date and link. Just connect the extractor blocks. And don’t forget to connect the feed builder block to the pipe output!
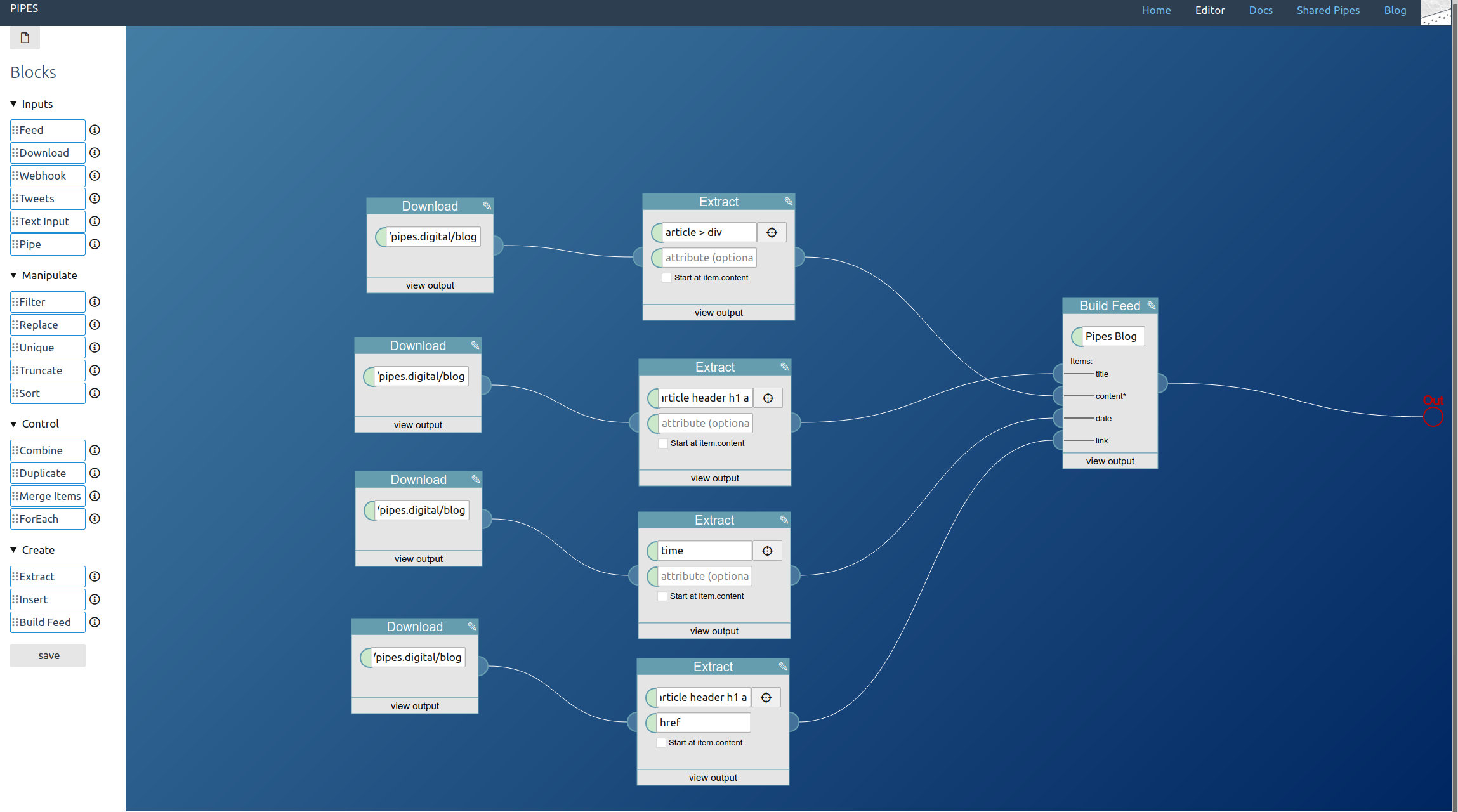
Now we can look at the preview:
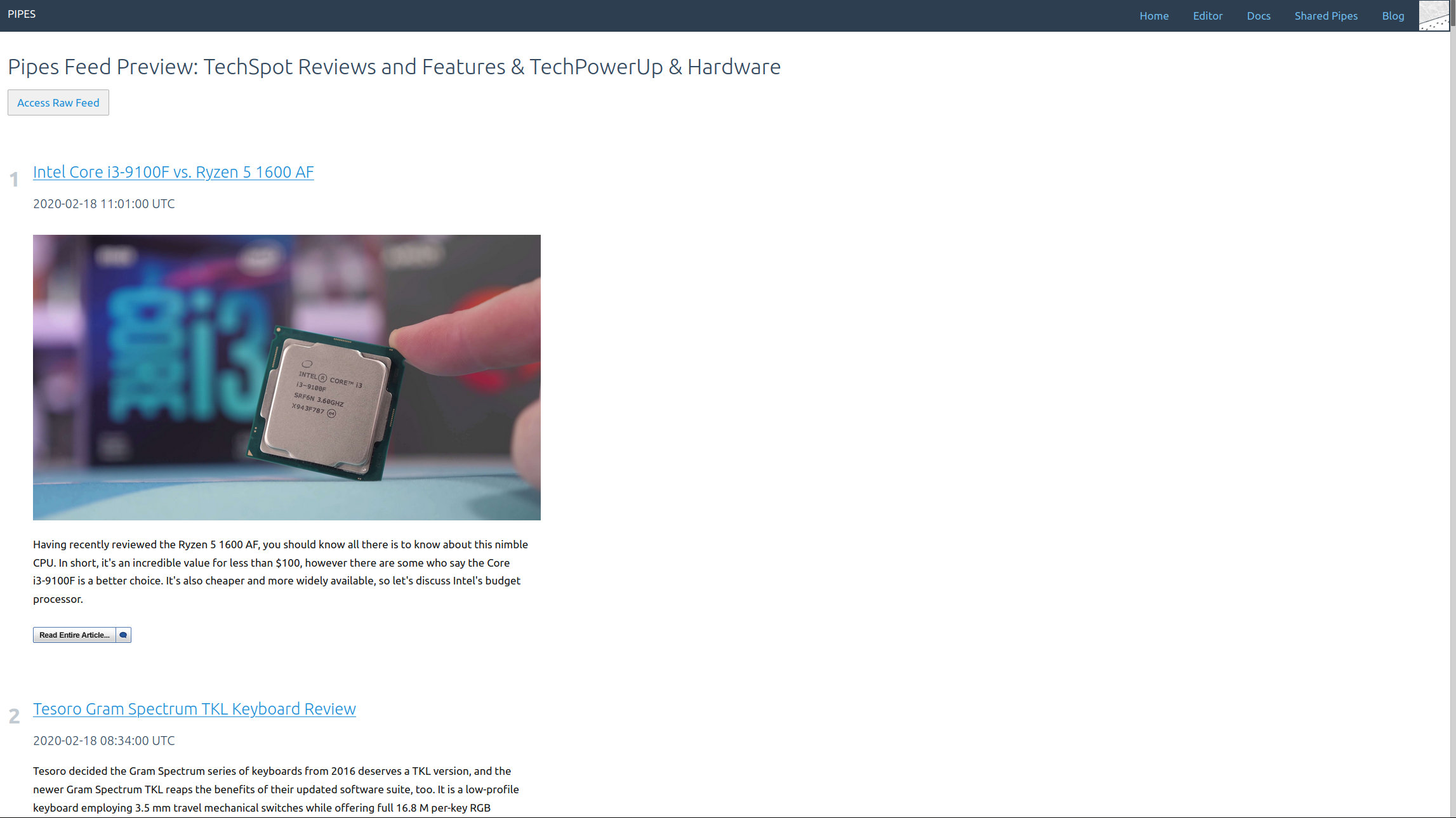
Perfect. If the blog didn’t have a feed already, with this newly created feed it could be read with an RSS reader anyway.
The pipe I created for this article is here, you can fork it to use it as a starting point for your own custom feed.
